Es steht so mittel: Mittelstand und IT-Sicherheit
Im Zuge der Digitalisierung werden immer mehr Informationen digital gespeichert, bearbeitet und verteilt. Während in kleineren Unternehmen oft eher eine verhältnismäßig geringe Menge an Daten verarbeitet wird und davon ein Großteil immer noch analog, verarbeiten mittelständische und große Unternehmen Informationen heute meist vorwiegend digital. Durch die Integration und automatisierte Verwaltung von – häufig sensiblen – Daten in Netzwerkstrukturen ergeben sich zwangsläufig Schwachstellen, die die Sicherheit der Informationen gefährden.
Die steigende Komplexität von Prozessen und Anwendungen führt fast unvermeidbar zu Fehlern in der Entwicklung, Wartung oder Handhabung. Zwar sind nicht alle Fehler sicherheitskritisch: Häufig greifen die Schutzmechanismen von Betriebssystemen und verwendeter Software, bevor ein Schaden entstehen kann. Doch mit der wachsenden Abhängigkeit von funktionierenden und vertrauenswürdigen Systemen wachsen auch die Risiken für deren Anwender*innen.
Besondere Gefährdung des Mittelstands
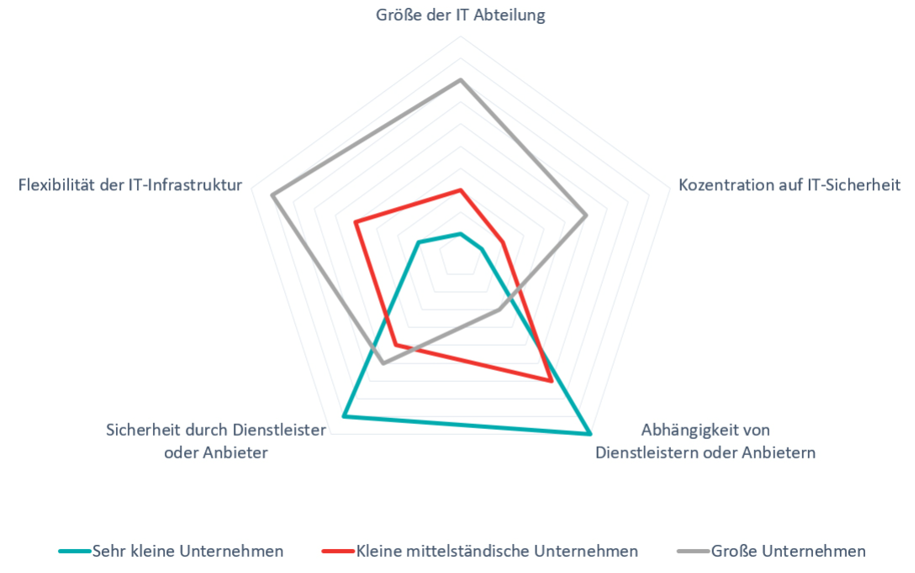
Dabei sind mittelständische Unternehmen bzw. KMU besonders gefährdet: Den Grundstein hierfür legt die im Unternehmen verwendete IT-Infrastruktur. Sehr kleine Unternehmen, beispielsweise Einzelunternehmen, haben in der Regel keine eigens eingerichtete IT-Infrastruktur. Hier kommen häufig etwa Router zum Einsatz, wie sie auch in privaten Haushalten verwendet werden, um eine Verbindung zum Internet zu ermöglichen. Kommunikationswege wie etwa E-Mail oder eine Webseite werden meist von großen Anbietern wie Google Mail oder Strato bereitgestellt. Der Vorteil hierbei ist ein geringer Aufwand für die Unternehmen und eine relativ hohe Sicherheit durch die Verwendung von Systemen professioneller Anbieter, da diese starke Sicherheitskonfigurationen für ihre Geräte (etwa eine FritzBox) und Systeme (zum Beispiel Webhosting oder Webmail) bereitstellen und in der Regel auch die nötigen Ressourcen dazu haben.
Nachteile bestehen in der Abhängigkeit vom Anbieter beziehungsweise von Dienstleistenden, die etwa bei der Einrichtung und Instandhaltung kontaktiert werden müssen. Zusätzlich ist eine derartig aufgebaute IT-Infrastruktur meist nicht sehr flexibel in ihren Konfigurationsmöglichkeiten oder bietet irgendwann nicht mehr alle Funktionen, die ein Unternehmen sich wünscht. Manche Unternehmen können oder wollen auch keinen Webmail-Anbieter einsetzen, da sie sich Sorgen um den Datenschutz machen, etwa wenn es sich um eine Arztpraxis handelt, die empfindliche Informationen verarbeiten muss.
Der nächste Schritt ist also der Einsatz flexiblerer IT-Systeme in einer gegebenenfalls wachsenden IT-Abteilung. Sich mit diesen Systemen auseinanderzusetzen stellt jedoch die meisten KMU vor Probleme. In diesem Fall wenden sich Unternehmen häufig an externe Dienstleister. Zwar wird dadurch das Unternehmen anpassungsfähiger in seiner IT. Aber meist ist der Fokus weder bei den Unternehmen noch bei ihren externen Dienstleistern auf IT-Sicherheit ausgerichtet, was zur Folge hat, dass potentielle Angriffswege entstehen, die ein großer Anbieter möglicherweise geschlossen hätte.
Große Unternehmen brauchen ein hohes Maß an Flexibilität und haben in der Regel auch eine entsprechende IT-Abteilung. Sie sind sich der Tragweite einer gut ausgeprägten IT-Sicherheit eher bewusst und besitzen im Zweifel die notwendigen Ressourcen, diese einzurichten und zu warten. Und wenn ein externer Dienstleister zu Rate gezogen werden muss, wird dieser meist entsprechende Schwerpunkte auf IT-Sicherheit vorweisen können.
Risiken für KMUs
Damit sind KMU von den drei vorgestellten Unternehmensgrößen am schwächsten aufgestellt, wenn es um ihre IT-Sicherheit geht, da sie zwar in ihren digitalen Unternehmensprozessen vielseitiger werden müssen, gleichzeitig aber aus unterschiedlichen Gründen selten den notwendigen Schwerpunkt auf IT-Sicherheit legen können.
Es müssen daher Maßnahmen ergriffen werden, die sowohl von technischen Aspekten einer Offenlegung der Schwachstelle (Disclosure) abhängig sind als auch von der Kommunikation mit möglichen Betroffenen, beispielsweise Kunden. Gleichzeitig muss gegebenenfalls die Öffentlichkeit informiert werden, bzw. die Bekanntmachung der Schwachstelle ist als Teil eines angemessenen Krisenmanagements zu etablieren. Häufig haben KMU keine ausreichende Erfahrung im Bereich der IT-Sicherheit. Dieser Mangel an Erfahrung erschwert den Umgang mit den Prozessen, die kritische Schwachstellen mit sich bringen, da die Unternehmen dadurch schlecht auf Sicherheitsvorfälle vorbereitet sind.
Formen von Schwachstellen
Im Bereich der Informationstechnik gibt es ein sehr breites Spektrum an möglichen Schwachstellen und Systemen, in denen diese auftauchen können. Vulnerabilities können sowohl in Hard- als auch in Software vorhanden sein – und sie können die unterschiedlichsten Ursachen haben: Diese erstrecken sich von veralteten Lizenzen oder Systemen über Verschleißerscheinungen eingesetzter Hardware bis hin zu Konfigurationsfehlern bei der Einrichtung oder Wartung. Die Möglichkeiten, einzelne schwerwiegende Schwachstellen in eingesetzten Systemen zu haben – beziehungsweise eine Kombination aus mehreren kleineren Schwachstellen, die zusammen eine kritische ergeben –, sind nahezu unüberschaubar vielfältig. Daher werden diese in der Mehrheit der Fälle, sofern sie keine direkt ersichtlichen gravierenden Auswirkungen haben, nicht als solche entdeckt.
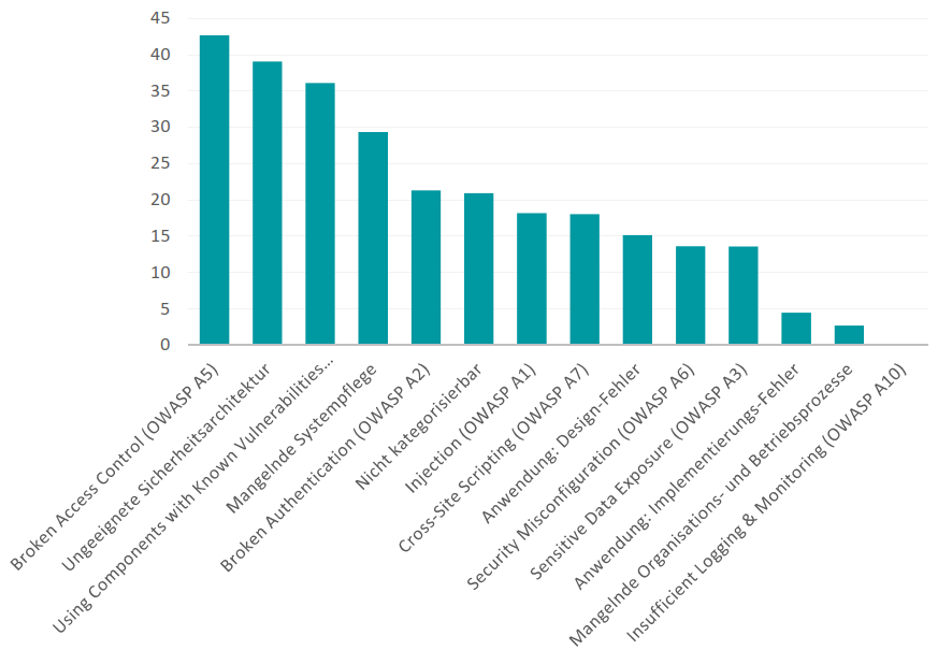
Um eine repräsentative Übersicht der häufigsten Sicherheitsvorfälle in diesem Bereich wiedergeben zu können, wurden Daten der HiSolutions AG ausgewertet. Hierbei wurden die betreuten Sicherheitsvorfälle sowie Penetrationstests der Jahre 2016 bis 2019 nach der Vorgabe der OWASP Top Ten kategorisiert und anschließend jeweils nach Häufigkeit des Aufkommens und Kritikalität der entsprechenden Kategorie bewertet.
So ist beispielsweise die Kategorie „Mangelnde Systempflege“, die sich auf ein unzureichendes Patchmanagement bei Webservern oder die Verwendung trivialer Passwörter bezieht, 2019 in 56,7% aller Fälle bei Kunden der HiSolutions AG nachgewiesen worden.
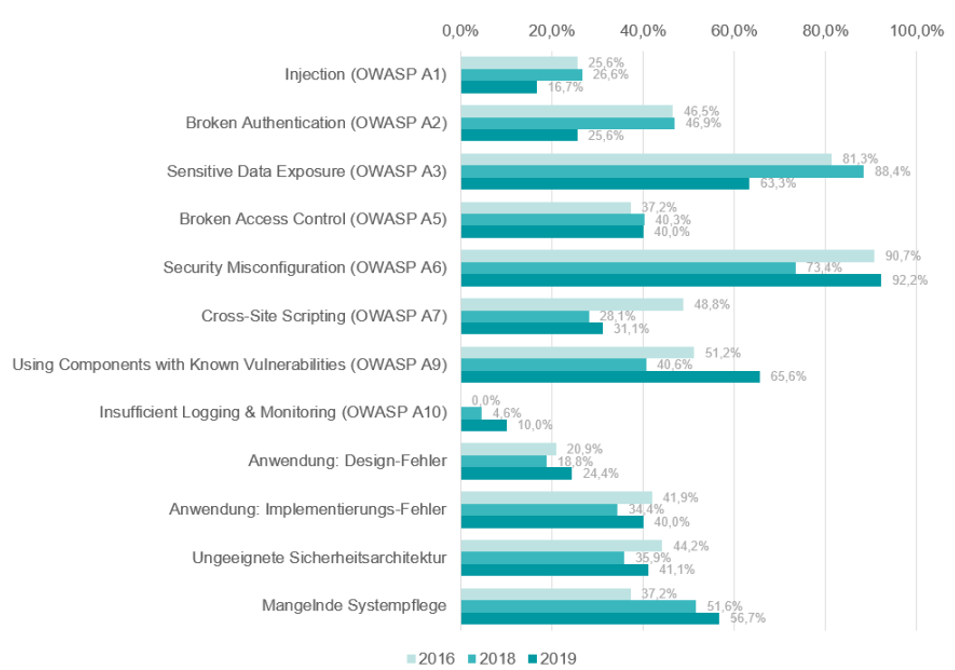
Es kann beobachtet werden, dass besonders Findings innerhalb der Kategorien der Authentifizierung von Nutzer*innen, der Verwendung veralteter Komponenten, der mangelnden Systempflege sowie einer ungeeigneten Sicherheitsarchitektur (beispielsweise eine unzureichende Konfiguration von Protokollen oder fehlende Konzepte im Netz-Management) kritische Schwachstellen für ein Unternehmen mit sich bringen.
Umgang mit Security in KMUs
Die Risiken für KMU, die von Schwachstellen in der IT-Sicherheit ausgehen, sind enorm vielfältig. Sie reichen von geringen Gefährdungen, etwa der Verlangsamung alltäglicher Prozesse und Aufgaben, bis hin zu existenzgefährdenden Krisen. Dabei steigert der Einsatz jedes Systems, welches in der Infrastruktur eingesetzt wird, die potentiellen Möglichkeiten eines Auftretens einzelner Schwachstellen beziehungsweise einer Kette von Schwachstellen exponentiell. Unternehmen betreiben in der Regel deutlich zu wenig Aufwand betreiben, mögliche Schwachstellen frühzeitig zu erkennen oder diese zu eliminieren, wodurch sie im Großteil der Vorfälle nicht ausreichend vorbereitet sind.
Es lässt sich festhalten, dass die Hürden im Umgang mit Vulnerabilities und eventuell daraus resultierender Vorfälle, im Speziellen was die interne und externe Kommunikation angeht, sehr vielfältig sind und ohne externe Hilfe nicht angemessen bewältigt werden können. Unternehmen, beziehungsweise Entscheidungsträger*innen, die mit der Thematik der IT-Sicherheit nicht vertraut sind, treffen häufig Entscheidungen, die mehr schaden als nutzen. Das Sparen von Ressourcen bei der Einrichtung und Wartung der eigenen IT-Infrastrukturen, bei der Auswahl externer Dienstleister oder beim Aufbau einer eigenen IT-Abteilung hat in der Regel negative Folgen für ein Unternehmen, die unter Umständen später nur schwer auszubessern sind.
Eine frühzeitige Auseinandersetzung mit den unternehmenseigenen Prozessen sowie eine zielführende Verteilung von Expertisen und Aufgaben haben einen beträchtlichen Anteil an der Sicherheit eines Unternehmens. Dafür muss speziell die IT-Sicherheit mehr in den Fokus rücken und mit entsprechenden Ressourcen gefördert werden. Hierzu gehören unter anderem die regelmäßige Auseinandersetzung mit möglichen Schwachstellen eingesetzter Systeme, die Schulung sämtlicher Mitarbeitenden sowie die Einführung von Prozessen und Maßnahmen für den Ereignisfall.
Fazit
Es muss davon ausgegangen werden, dass Software – egal ob eigens entwickelt oder von Drittanbietern – Bugs hat. Und solange Software Fehler beinhaltet, werden diese auch Schwachstellen enthalten. Wenn eine solche Schwachstelle entdeckt wird und ein Unternehmen davon erfährt, sollte die Entdeckung gründlich untersucht werden, auch oder gerade dann, wenn es an einem detaillierten technischen Verständnis der Problematik mangelt. Die Idee, sich gegen den Melder der Schwachstelle zu wehren, indem Strafverfolgungsbehörden oder Anwälte eingeschaltet werden, ist zwar nicht in jedem Fall zwingend falsch (etwas wenn der Verdacht der Erpressung besteht). Es sollte jedoch eine angemessene und ausreichende Kommunikation mit Meldenden stattfinden, die deren Motivationen herausstellt und prüft, ob entsprechende rechtliche Schritte wirklich notwendig sind. Im schlimmsten Fall können verfrühte Schritte dieser Art zu negativer Aufmerksamkeit in der Öffentlichkeit führen, die unter Umständen schädlicher für das Unternehmen sein kann als die initiale Schwachstelle. Oder aber es werden wohlmeinedne Sicherheitsforscher*innen vergrault, die einen Beitrag zur Security der Organisation hätten leisten können und wollen.
Unabhängig von der Motivation von Melder*innen sollte ein Unternehmen bei kritischen Schwachstellen stets die Verantwortung selbst übernehmen. Eine transparente Kommunikation, extern und intern, die die gefundene Schwachstelle annimmt und ein rasches Handeln vermittelt, hilft dabei das Vertrauen bei Kund*innen, Mitarbeitenden oder dritten Interessengruppen zu fördern und beweist Integrität. Außerdem beugt sie eventuellen Annahmen, die Sicherheits-Situation sei kritischer als sie tatsächlich ist, vor. Die richtige Balance zwischen offener Kommunikation und Diskretion ist schwierig, aber essentiell.
Praktische Hinweise finden Sie auch in unserer Checkliste: https://www.hisolutions.com/detail/checkliste-zur-cybersecurity-fuer-kleine-und-mittlere-einrichtungen