Die Uhr läuft: Warum die Post-Quanten-Migration jetzt beginnen muss
Be liberal in what you accept – don’t trust anything. Das Thema Vertrauen in Netzwerken hat einen radikalen Wandel vollzogen. Wo es in den Anfangszeiten der modernen IT noch mit einer guten Portion Vertrauensvorschuss voranging, ist heute große Skepsis angebracht. Und mit Quantencomputern steht bereits der nächste Paradigmenwechsel bevor.
Vertrauen im Wandel – eine kurze Geschichte der Netzwerksicherheit
„In general, an implementation should be conservative in its sending behavior, and liberal in its receiving behavior.” Diesen Satz formulierte Jon Postel in den Anfangstagen des Internets. Mit diesem Satz in seinem RFC 760 zum Internet-Protokoll im Jahr 1980 sollte er die Netzwerkentwicklung nachhaltig prägen. Nur ein Jahr später, im RFC 793 zur Spezifikation des TCP, erhob er diesen Gedanken explizit zum Robustheitsprinzip: „Be conservative in what you do, be liberal in what you accept from others.”
Zum damaligen Zeitpunkt galt dies als pragmatische Ingenieursweisheit. Es entsprach dem Geist einer Zeit, in der das Netz eine überschaubare Gemeinschaft von Universitäten und Forschungseinrichtungen verband. Man kannte sich. Man vertraute sich. Und genau dieses Grundvertrauen wurde zum Fundament eines Netzwerks, das nie für das gebaut wurde, was es heute ist: Ein globales Netzwerk, wo die nächste Gefahr fürs eigene Netzwerksegment nur einen Hop entfernt ist.
Als das Internet in den 1990er-Jahren seinen Weg in Unternehmen fand, wurde schnell klar, dass Postels großzügiges Prinzip allein nicht ausreichen würde. Nicht jeder Teilnehmende im Netz hatte gute Absichten. Die Antwort der IT-Sicherheit folgte einer Logik, die so alt ist wie die Zivilisation selbst: Man baute eine Mauer. Das Modell des Perimeterschutzes war geboren – eine klare Grenze zwischen Innen und Außen. Firewalls filterten den Datenverkehr an den Toren. Was innerhalb der Mauern lag, galt als vertrauenswürdig. Postels Prinzip der Großzügigkeit lebte dort weiter – aber nur noch im geschützten Inneren.
Doch Mauern haben ein grundsätzliches Problem: Sie schützen nur, solange niemand sie überwindet. Wer einmal drinnen ist – ob berechtigt oder nicht – genießt volles Vertrauen. Und die Welt jenseits der Mauern wurde größer, feindseliger, unübersichtlicher.
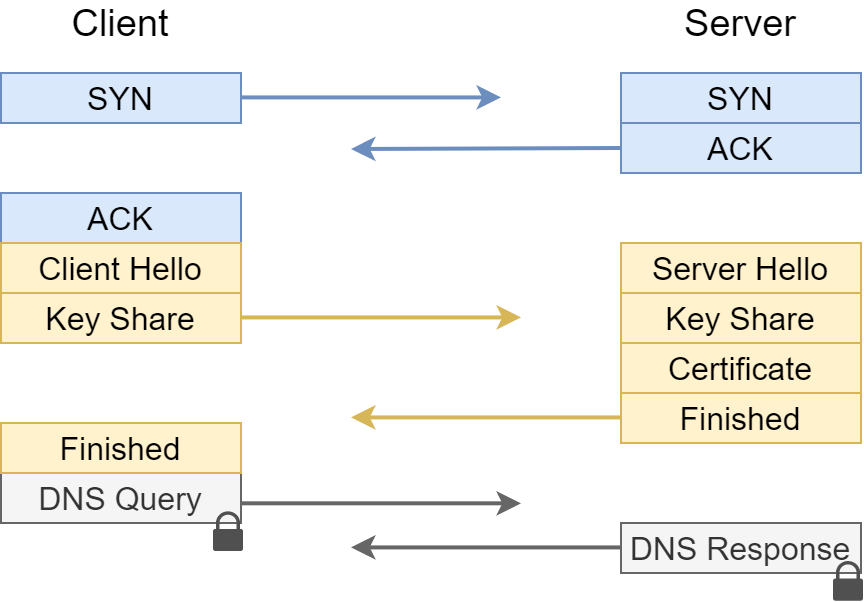
Parallel dazu reiften kryptografische Verfahren heran, die eine fundamental andere Art von Vertrauen ermöglichten: nicht mehr Vertrauen durch Zugehörigkeit zu einem Netzwerk, sondern Vertrauen durch mathematisch überprüfbare Identität. SSL und sein Nachfolger TLS sicherten die Kommunikation zwischen Endpunkten. VPNs schufen verschlüsselte Tunnel zwischen perimetergeschützten Umgebungen über unsicheres Terrain. Public-Key-Infrastrukturen etablierten Vertrauensketten, die an keine physische Netzwerkgrenze gebunden waren. Was als Ergänzung zum Perimeterschutz begann, wurde zunehmend zu einer eigenständigen Sicherheitsschicht – und schließlich zu einer Alternative.
Nach der Jahrtausendwende formulierte John Kindervag bei Forrester Research im Jahr 2010 den konsequenten Schluss aus dieser Entwicklung: Zero Trust. Das Prinzip ist in seiner Radikalität bemerkenswert einfach: Vertraue niemandem. Verifiziere immer alles. Kein Netzwerkstandort, keine IP-Adresse, keine Firewall-Regel gewährt Vertrauen – nur die kryptografisch gesicherte, kontinuierlich überprüfte Identität eines Akteurs und der Kontext seiner Anfrage.
Zero Trust ist damit nicht nur eine technische Architektur. Es ist die konsequente Umkehrung von Postels Erbe. Wo das Robustheitsprinzip noch sagte “Sei großzügig in dem, was du akzeptierst”, antwortet Zero Trust “Akzeptiere nichts, was sich nicht zweifelsfrei ausweisen kann”. Aus implizitem Vertrauen wurde explizite Verifikation. Was einst als Tugend galt – Offenheit, Toleranz gegenüber dem Unbekannten – wurde in einer feindlichen Umgebung zur Schwachstelle.
Die Geschichte der Netzwerksicherheit ist damit auch eine Geschichte darüber, wie sich der Begriff des Vertrauens selbst gewandelt hat: vom sozialen Grundkonsens einer akademischen Gemeinschaft über die territoriale Logik befestigter Grenzen hin zu einem System, in dem Vertrauen nicht vorausgesetzt, sondern in jedem einzelnen Moment mathematisch bewiesen werden muss. Postel entwarf sein Prinzip für eine Welt, in der guter Wille die Regel war. Zero Trust wurde für eine Welt gebaut, in der man sich diesen guten Willen nicht mehr leisten kann.
Die vier Bedrohungsachsen der Kryptografie
Heute ist die Netzwerksicherheit fundamental von der Sicherheit der eingesetzten kryptografischen Verfahren abhängig. Diese Verfahren sehen sich vier zentralen Bedrohungsachsen ausgesetzt:
- Kontinuierliche Steigerung der Rechenleistung – was heute als sicher parametrisiert gilt, kann morgen durch brute-force-fähige Hardware fallen.
- Protokoll- und Implementierungsfehler – von Heartbleed (CVE-2014-0160) über ROBOT (CVE-2017-17382, CVE-2017-6168) bis hin zu Timing-Seitenkanalangriffen. Die Lücke liegt oft nicht im Algorithmus, sondern im Code.
- Mathematische Fortschritte – neue analytische Methoden können die effektive Sicherheit eines Verfahrens über Nacht reduzieren, wie zuletzt die Diskussionen um Angriffe auf gitterbasierte Verfahren zeigten.
- Quantencomputer – ein kryptografisch relevanter Quantencomputer (CRQC) würde RSA, ECDSA und Diffie-Hellman mittels Shors Algorithmus in polynomialer Zeit brechen.
Die strategische Antwort auf diese Bedrohungen trägt einen Namen: Kryptoagilität – die architektonische Fähigkeit, kryptografische Verfahren in bestehenden Systemen zügig und ohne disruptive Umbaumaßnahmen austauschen zu können (vgl. Fraunhofer SIT: Kryptoagilität). Kryptoagilität ist keine Option mehr. Sie ist eine Überlebensfähigkeit.
Die Quantenbedrohung: Näher als viele glauben
Lange Zeit galt ein kryptografisch relevanter Quantencomputer (CRQC) als akademische Spekulation. Doch die Faktenlage hat sich verdichtet:
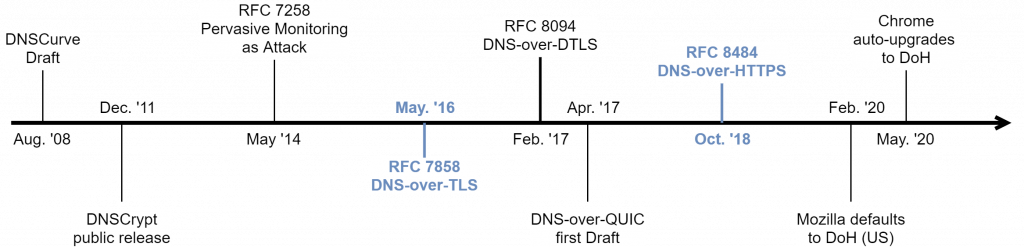
- 2015 veröffentlichte Prof. Michele Mosca, Mitgründer des Institute for Quantum Computing an der University of Waterloo, eine vielbeachtete Risikoabschätzung: Die Wahrscheinlichkeit, dass die heute eingesetzte Public-Key-Kryptografie durch einen Quantencomputer gebrochen wird, liege bei ca. 14 % bis 2026 und bei 50 % bis 2031 (Mosca 2015, eprint.iacr.org/2015/1075).
- 2016 rief das NIST den Standardisierungsprozess für Post-Quantum Cryptography (PQC) ins Leben. In der Begründung (NIST IR 8105) hieß es unmissverständlich: Ein CRQC könne innerhalb von ein bis zwei Jahrzehnten zur realen Bedrohung werden.
- August 2024 veröffentlichte das NIST die finalen PQC-Standards: FIPS 203 (ML-KEM, basierend auf CRYSTALS-Kyber), FIPS 204 (ML-DSA, basierend auf CRYSTALS-Dilithium) und FIPS 205 (SLH-DSA, basierend auf SPHINCS+). Der Werkzeugkasten für die Post-Quanten-Ära existiert. Die Standards sind da.
- 2025 und darüber hinaus setzt sich die Standardisierungsdynamik fort: Mit FIPS 206 (FN-DSA, basierend auf FALCON) steht ein weiterer NIST-Standard für digitale Signaturen kurz vor der Veröffentlichung – ein Verfahren, das insbesondere durch kompakte Signaturen bei gleichzeitig moderaten Schlüsselgrößen besticht. Parallel dazu treibt die ISO die Standardisierung zweier Verfahren voran, die bewusst auf konservativere – und damit besser verstandene – mathematische Grundlagen setzen: FrodoKEM, dessen Sicherheit auf dem allgemeinen Learning-with-Errors-Problem (LWE) ohne Gitterstruktur basiert, sowie Classic McEliece, ein codebasiertes Verfahren mit über 40 Jahren kryptoanalytischer Resistenz (vgl. BSI TR-02102-1, Kryptografische Verfahren: Empfehlungen und Schlüssellängen, Version 2026-01, Abschnitte 2.4.1 & 2.4.2). Damit zeichnet sich ein diversifiziertes PQC-Ökosystem ab – eines, das nicht von einer einzelnen mathematischen Annahme abhängt und der Forderung nach Kryptoagilität auch auf Verfahrensebene Rechnung trägt.
Ein bemerkenswertes Detail verdient besondere Aufmerksamkeit: Anders als bei der Kernfusion, die stets „in 50 Jahren“ einsatzbereit sein soll – egal, wann man fragt –, hat sich die Einschätzung der Krypto-Community zum Zeithorizont eines CRQC über das letzte Jahrzehnt nicht nach hinten verschoben. Die Prognosen konvergieren beständig auf den Zeitraum 2030 bis 2035. Das ist keine vage Zukunft. Das ist dieses Jahrzehnt.
Harvest Now, Decrypt Later – die Bedrohung von heute
Die Quantenbedrohung ist keine Zukunftsmusik – sie materialisiert sich bereits. Unter dem Paradigma „Harvest now, decrypt later“ (HNDL) werden heute verschlüsselt übertragene Daten von staatlichen Akteuren und nachrichtendienstlichen Einheiten systematisch abgefangen und gespeichert, um sie zu einem späteren Zeitpunkt mit einem CRQC zu entschlüsseln.
Betroffen sind alle Daten, deren Vertraulichkeit über den Zeitpunkt der Übertragung hinaus Bestand haben muss: Staatsgeheimnisse, medizinische Daten, Geschäftsgeheimnisse, Verhandlungspositionen, Quellenschutz. Wer heute verschlüsselt kommuniziert, aber klassische Verfahren nutzt, gewährt retrospektive Einsicht, sobald ein CRQC verfügbar ist.
Die Bedrohung durch Quantencomputer ist daher nicht erst in zehn Jahren relevant. Sie ist es bereits jetzt.
Moscas Ungleichung: Warum die Schere bereits aufgegangen ist
Die eigentliche Eskalation liegt nicht im Quantencomputer selbst – sie liegt in der Asymmetrie zwischen Angriffs- und Verteidigungstempo.
Filippo Valsorda, einer der profiliertesten Stimmen im Bereich angewandter Kryptografie, hat diese Dynamik in einer vielbeachteten Analyse (words.filippo.io/crqc-timeline) auf den Punkt gebracht: Mit jedem Durchbruch in der Quantenfehlerkorrektur komprimiert sich die prognostizierte Zeitlinie für einen CRQC, während sich gleichzeitig die für eine vollständige kryptografische Migration benötigte Zeit als erschreckend lang erweist.
Das formalisiert Moscas Ungleichung:
x + y < z
x = benötigte Migrationszeit, y = geforderte Schutzfrist der Daten, z = verbleibende Zeit bis zum CRQC
Sobald x + y > z (die Summe aus Migrationszeit und Schutzbedarf die verbleibende Zeit bis zum CRQC übersteigt) ist das Zeitfenster für eine rechtzeitige Absicherung unwiderruflich geschlossen. Jeder Tag ohne begonnene Migration ist ein Tag, an dem die Schere weiter aufgeht. Es gibt keinen Weg, verlorene Zeit zurückzugewinnen.
Die konvergierenden Signale sind eindeutig: Google demonstrierte im Dezember 2024 mit dem Quantenprozessor Willow erstmals eine skalierende Quantenfehlerkorrektur unterhalb der Fehlerschwelle, wie sie seit den 1990er‑Jahren theoretisch vorhergesagt wurde. Die Ergebnisse, veröffentlicht in der wissenschaftlichen Fachzeitschrift Nature, zeigen, dass logische Qubits mit wachsender Größe exponentiell zuverlässiger werden. Ein Durchbruch, der Quantencomputing von einem physikalischen Experiment zu einer ingenieurtechnisch beherrschbaren Technologie und damit das Narrativ „Quantencomputer sind noch Jahrzehnte entfernt“ endgültig obsolet macht.
IBM, Google und Microsoft haben in den Jahren 2024–2025 konsistente Roadmaps veröffentlicht, die jeweils explizit auf fehlerkorrigierte (fault‑tolerante) Quantensysteme abzielen (Roadmap IBM, Roadmap Google, Roadmap Microsoft). Obwohl sie unterschiedliche Hardware‑Ansätze verfolgen, konvergieren ihre Zeitpläne auf die späten 2020er Jahre, mit ersten großskaligen, logisch geschützten Quantensystemen bis zum Ende dieses Jahrzehnts.
Nationale Sicherheitsbehörden gehen heute explizit davon aus, dass staatliche Akteure bereits verschlüsselten Datenverkehr massenhaft erfassen und langfristig speichern, um ihn mit zukünftigen kryptografischen Durchbrüchen – insbesondere durch Quantencomputer – nachträglich zu entschlüsseln. Dieses bereits weiter oben benannte Vorgehen ist als Harvest Now, Decrypt Later (HNDL) bekannt und wird in aktuellen Regierungs‑, Industrie‑ und Aufsichtsberichten als gegenwärtige, operative Realität beschrieben (stateofsurveillance.org, federalreserve.gov).
Damit hat sich die zentrale Frage verschoben: Es geht nicht mehr darum, ob die heutige Public-Key-Kryptografie fällt, sondern ob unsere Infrastrukturen schnell genug umgerüstet sein werden, wenn es so weit ist.
Was jetzt zu tun ist
Das klingt düster, ist aber kein Grund zur Resignation. Es ist ein Grund zum Handeln. Der Werkzeugkasten existiert. Die Standards sind verabschiedet. Die Migrationspfade werden klarer. Was fehlt, ist nicht Technologie. Was fehlt, ist Entschlossenheit und begonnene Arbeit.
Fünf Schritte, die Sie diese Woche anstoßen können:
- Kryptografisches Inventar erstellen: Sie können nicht migrieren, was Sie nicht kennen. Erfassen Sie systematisch, wo in Ihrer Infrastruktur welche kryptografischen Verfahren im Einsatz sind – von TLS-Konfigurationen über VPN-Tunnel bis hin zu Signaturverfahren in CI/CD-Pipelines und Firmware-Updates. Das BSI bezeichnet diesen Schritt als unverzichtbare Grundlage jeder Migrationsstrategie.
- Daten nach Schutzfrist klassifizieren: Nicht alle Daten sind gleich betroffen. Identifizieren Sie Assets, deren Vertraulichkeit oder Integrität über 2030 hinaus gewährleistet sein muss. Diese Daten stehen unter akuter HNDL-Bedrohung und erfordern priorisierte Migration.
- Kryptoagilität architektonisch verankern: Kryptografische Verfahren dürfen nicht hart in Anwendungen und Protokolle eingebrannt sein. Abstraktionsschichten, konfigurierbare Cipher-Suites und modulare Kryptobibliotheken sind die Voraussetzung dafür, dass die PQC-Migration nicht zum Großprojekt mit Zeithorizont 2035 wird.
- Hybride Ansätze jetzt evaluieren und pilotieren: Die NIST-Standards (ML-KEM, ML-DSA, SLH-DSA) sind final. Große Anbieter wie Cloudflare, Google und Signal setzen bereits hybride Verfahren (klassisch + PQC) in Produktion ein. Pilotieren Sie hybride TLS-Konfigurationen und Key-Encapsulation in Ihren kritischsten Kommunikationskanälen.
- Migration als strategisches Programm aufsetzen – nicht als Technikprojekt: Selbst bei guter Kryptoagilität bleibt die PQC-Migration mehr als ein Algorithmentausch. Sie betrifft Procurement-Anforderungen, Compliance-Nachweise, Partnerkommunikation, Zertifikats-Lifecycles und Legacy-Systeme, die sich nicht per Konfigurationsänderung umstellen lassen. Diese organisatorische Breite erfordert ein Mandat auf Leitungsebene, ein dediziertes Budget und einen realistischen, aber ambitionierten Zeitplan. Kryptoagilität verkürzt die technische Migrationszeit erheblich. Aber nur ein strategisches Programm stellt sicher, dass auch alles drumherum rechtzeitig mitkommt.
Moscas Ungleichung ist keine Abstraktion. Sie ist eine Stoppuhr – und sie läuft. Jeder Tag, an dem Ihre Organisation die Post-Quanten-Migration nicht aktiv vorantreibt, ist ein Tag, an dem sich das Zeitfenster für eine geordnete Transition weiter schließt. Die gute Nachricht: Wer heute beginnt, hat noch die Chance, vor der Kurve zu sein statt hinter ihr. Die Standards stehen. Die Werkzeuge reifen. Die Early Movers haben angefangen.
Die Frage ist nicht mehr, ob Sie migrieren müssen. Die Frage ist, ob Sie es rechtzeitig tun.
Fangen Sie an. Heute.