KI-Agenten anfällig für einfache gefährliche Angriffe
Es lässt sich eine signifikant zunehmende Verwendung von KI-Agenten in verschiedenen Bereichen zur Automatisierung von Aufgaben und zur Unterstützung bei Entscheidungsprozessen beobachten (i. d. R. mit Large Language Models – LLM). Die Kompetenz, diese KI-Systeme effektiv zu nutzen und zu steuern, gewinnt damit an Bedeutung.
Doch wie sicher sind diese KI-Agenten?
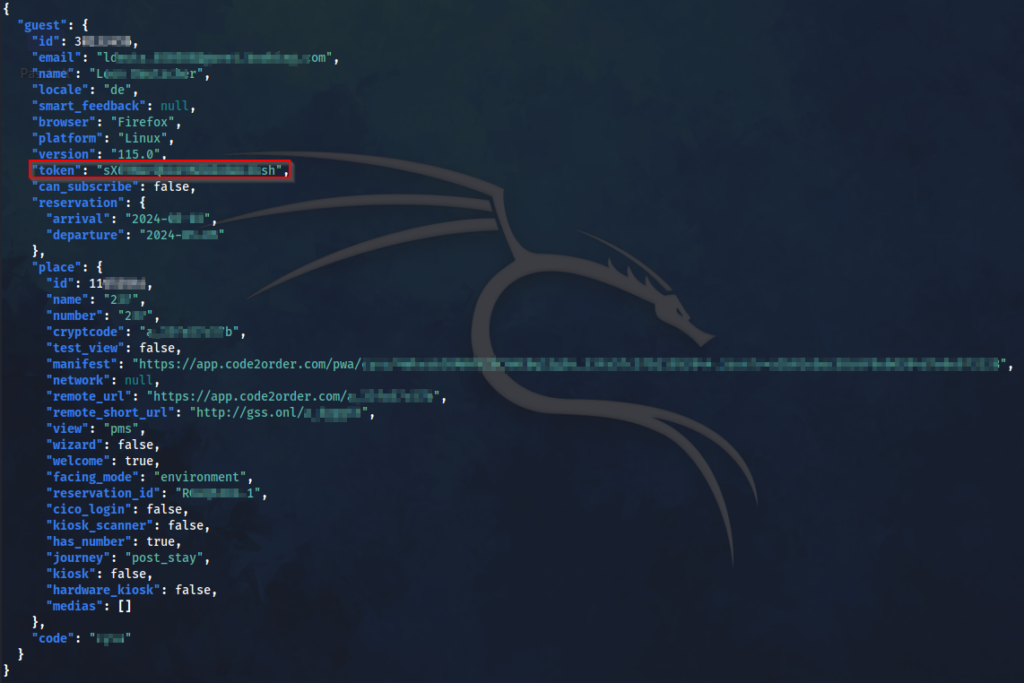
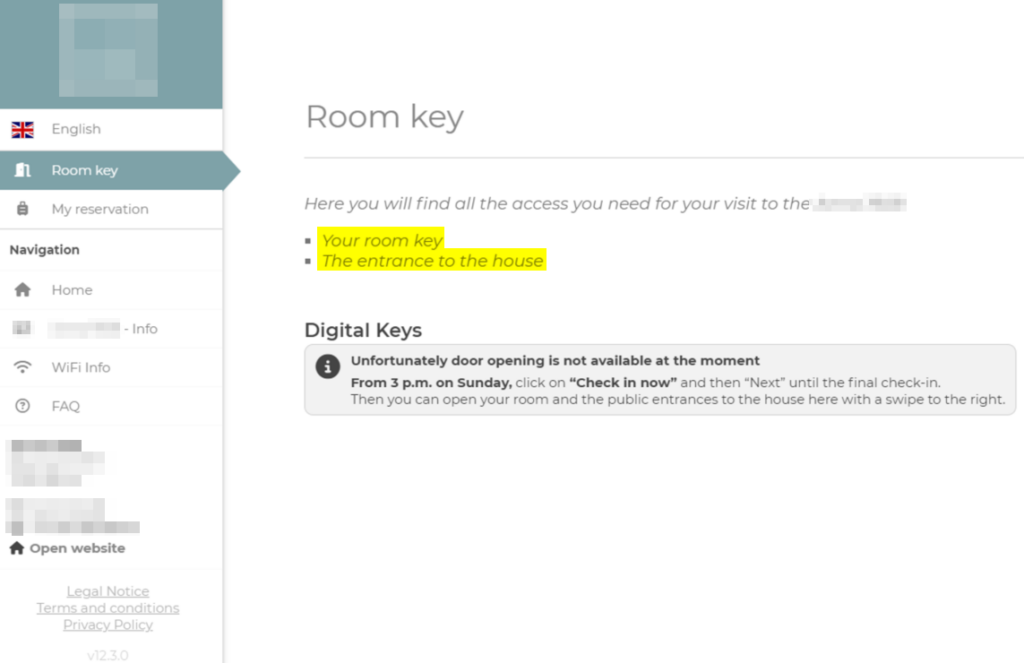
Eine aktuelle Studie mit dem Titel „Commercial LLM Agents Are Already Vulnerable to Simple Yet Dangerous Attacks“ beleuchtet die Sicherheits- und Datenschutzlücken von kommerziellen LLM-Agenten und zeigt, dass diese oft anfällig für einfache, aber gefährliche Angriffe sind.
Die Autoren der Studie haben eine umfassende Taxonomie der Angriffe erstellt, die Bedrohungsakteure, Ziele, Einstiegspunkte, Sichtbarkeit des Angreifenden, Angriffstechniken und die inhärenten Schwachstellen der Agenten-Pipelines kategorisiert. Die systematische Analyse zeigt, dass die Integration von LLMs in größere Systeme neue Sicherheitsherausforderungen mit sich bringt, die über die bekannten Schwachstellen isolierter LLMs hinausgehen.
Um die praktischen Auswirkungen dieser Schwachstellen zu demonstrieren, führten die Autoren eine Reihe von Angriffen auf populäre Open-Source- und kommerzielle Agenten durch, die bemerkenswert einfach umzusetzen waren und keine speziellen Kenntnisse im Bereich maschinelles Lernen erforderten. Dies unterstreicht die Dringlichkeit, Sicherheitsmaßnahmen zu verbessern und die Robustheit dieser Systeme zu erhöhen.
https://arxiv.org/html/2502.08586v1
https://www.linkedin.com/pulse/wenn-ki-agenten-zu-komplizen-werden-roger-basler-de-roca-qnrre