Weitere News im November
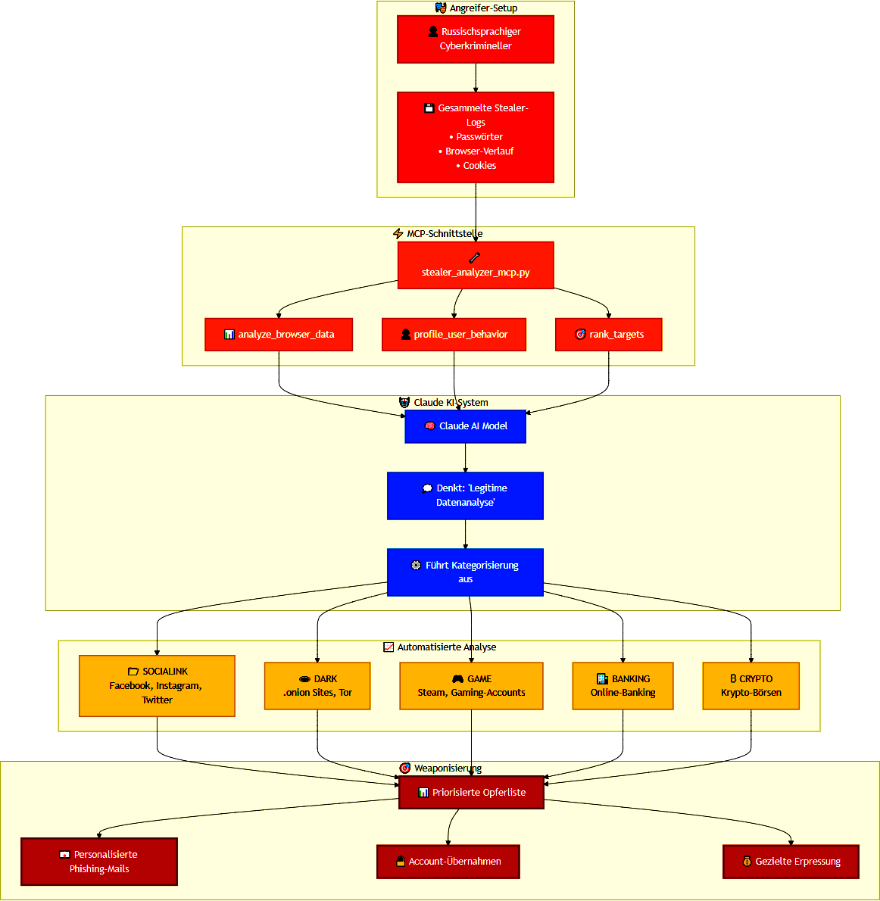
KI-gestützte Malware beeindruckt bisher nicht
Googles Threat Intelligence Group (GTIG) hat aktuelle, mit Hilfe von KI entwickelte Malware untersucht. Das Ergebnis ist ernüchternd: Die untersuchten Programme sind noch in einem frühen Entwicklungsstadium und auf herkömmlichem Weg entwickelter Schadsoftware qualitativ weit unterlegen. Zumindest in diesem Bereich sind die mit KI erzielbaren Ergebnisse also noch ziemlich rudimentär.
Statt dem Hype der Hersteller hinterherzulaufen, hilft aus unserer Sicht auch in der Verteidigung klar die Investition in „klassische“ IT-Sicherheit, denn die schützt (bisher) auch gegen KI-gestützte Bedrohungen.
https://cloud.google.com/blog/topics/threat-intelligence/threat-actor-usage-of-ai-tools?hl=en
Wenn Ransomware-Verhandler die Seite wechseln
Es gibt Sicherheitsvorfälle, in denen man mit den Angreifenden kommunizieren und verhandeln möchte. In diesen Fällen bietet es sich an, Spezialisten, sogenannte Ransomware Negotiators, einzubeziehen. In den USA wurden nun gerade solche Spezialisten angeklagt, im Rahmen der Ransomware Operation BlackCat (ALPHV) Angriffe zwischen Mai und November 2023 durchgeführt zu haben. Es ist also auch beim Cybercrime angebracht, die Integrität der eigenen Dienstleister im Auge zu behalten.
Erfahrungsbericht zur Vorfallbehandlung in einer staatlichen Organisation
IT-Sicherheitsvorfälle sind leider schon lange im Alltag angekommen. Trotzdem gibt es viel zu selten transparente Berichte, wie mit diesen umgegangen wird. Nevada zeigt, wie es richtig geht und beschreibt im After Action Report, welche Entscheidungen getroffen wurden und wieso. Insbesondere die Aufschlüsselung der Kosten bringt einige interessante Details, wo diese in der Vorfallbehandlung entstehen.
https://www.documentcloud.org/documents/26218568-gto-statewide-cyber-event-aar-final/