Aktiv ausgenutzte Schwachstellen häufen sich: Sicherheitslage verschärft sich quer durch die IT-Infrastruktur
Browser, VPNs, SD-WAN, Domain-Controller, MFT-Server und Mobile-Plattformen: In den letzten vier Wochen haben sich die Meldungen zu bereits aktiv ausgenutzten Schwachstellen auffällig verdichtet. Bemerkenswert ist, dass die in den Quellen beschriebenen Fälle unterschiedliche Produktkategorien betreffen, darunter Browser, VPN-/Firewall-Produkte, SD-WAN-Management, Domain-Controller, MFT-Server sowie Android- und Linux-Systeme. Betroffen sind ausgerechnet die Systeme, die in Unternehmen als besonders kritische Kontrollpunkte gelten.
Mehrere Herstellerwarnungen, Medienberichte und neue bzw. aktualisierte Einträge im CISA-KEV-Katalog zeigen, dass zuletzt mehrere Schwachstellen als aktiv ausgenutzt gemeldet wurden. Dieser Eindruck wird durch den Known Exploited Vulnerabilities Catalog der US-Behörde CISA gestützt, der genau solche Fälle bündelt und ausdrücklich als Priorisierungsgrundlage für das Schwachstellenmanagement empfiehlt.
Auffällig ist vor allem, wie breit die aktuelle Welle streut. Google hatte am 9. Juni 2026 eine weitere aktiv ausgenutzte Chrome-Zero-Day in der V8-Engine geschlossen; laut SecurityWeek ist es bereits die fünfte aktiv ausgenutzte Chrome-Zero-Day des Jahres 2026. Fast zeitgleich warnte Check Point vor einer kritischen VPN-/Firewall-Schwachstelle, die laut SecurityWeek von Akteuren rund um Qilin-Ransomware als Zero-Day ausgenutzt wurde und umgehend im CISA-KEV-Katalog landete.
Hinzu kommen mehrere Fälle in klassischer Unternehmensinfrastruktur. Cisco warnte Anfang Juni vor der aktiv ausgenutzten Schwachstelle CVE-2026-20245 in Catalyst SD-WAN Controller, Manager und Validator. Laut Cisco kann ein authentifizierter Angreifer unter bestimmten Voraussetzungen durch das Hochladen einer präparierten Datei Befehle mit Root-Rechten ausführen. Wichtig für die Einordnung: Die Lücke wurde zunächst als Zero-Day bekannt, die inzwischen aktualisierte Cisco-Advisory nennt jedoch verfügbare Software-Updates und empfiehlt eine zeitnahe Aktualisierung sowie die Prüfung möglicher Kompromittierungsindikatoren.
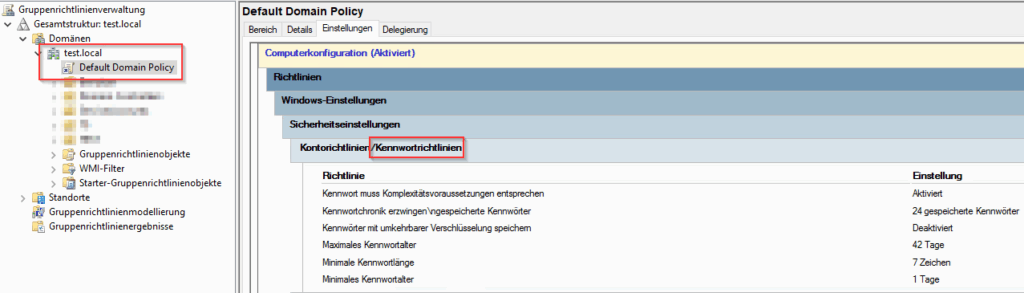
BleepingComputer berichtet, dass die belgische Cybersicherheitsbehörde CCB vor einer aktiven Ausnutzung von CVE-2026-41089 in Windows Netlogon warnt. Microsoft erklärte gegenüber BleepingComputer jedoch, man habe derzeit keine eigenen Erkenntnisse, die diese Einschätzung bestätigen. Für Unternehmen bleibt die Schwachstelle dennoch relevant, da sie Domain Controller betrifft und laut Microsoft ohne vorherige Anmeldung zur Remote-Code-Ausführung ausgenutzt werden kann.
Auch bei exponierten Dateiübertragungs- und Plattformdiensten häufen sich die Warnungen. SecurityWeek und Help Net Security berichteten Anfang Juni über die aktive Ausnutzung von CVE-2026-28318 in SolarWinds Serv-U; CISA setzte für US-Bundesbehörden eine Frist bis zum 19. Juni 2026, um den Fall zu adressieren. Gleichzeitig warnte BleepingComputer unter Berufung auf CISA vor aktiven Angriffen auf Android und Linux, darunter eine Android-Schwachstelle, die laut Google ohne Nutzerinteraktion ausnutzbar ist, sowie eine Linux-Kernel-Lücke mit Privilegieneskalation.
Die genannten Fälle betreffen Systeme, die in vielen Unternehmen für Webzugriff, Remote-Zugänge, Netzwerkverwaltung, Dateiübertragung und Identitätsdienste eingesetzt werden.
Die betroffenen Produkte liegen in den berichteten Fällen unter anderem im Bereich Browser, Remote-Zugriff, Netzwerkverwaltung, Dateiübertragung, mobile Plattformen und Identitätsinfrastruktur. Welche Auswirkungen eine Ausnutzung im Einzelfall hat, hängt jedoch vom betroffenen Produkt, der konkreten Schwachstelle und der jeweiligen Umgebung ab.
Die aktuellen Herstellerwarnungen und CISA-KEV-Einträge sprechen dafür, aktiv ausgenutzte Schwachstellen in Patch- und Mitigationsprozessen kurzfristig zu prüfen und gegebenenfalls priorisiert zu behandeln. Wer sich im Patch- und Exposure-Management noch stark an CVSS-Werten oder festen Wartungsfenstern orientiert, läuft Gefahr, auf reale Angriffsmuster zu spät zu reagieren. Der KEV-Katalog und die jüngsten Herstellerwarnungen zeigen, dass die relevanten Fälle derzeit oft genau dort auftauchen, wo schnelle Entscheidungen über Abschottung, Mitigations und Notfall-Patching nötig sind.
https://api.msrc.microsoft.com/sug/v2.0/en-US/vulnerability/CVE-2026-41089
https://chromereleases.googleblog.com/2026/06/stable-channel-update-for-desktop_0153744567.html
https://msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2026-41089
https://source.android.com/docs/security/bulletin/2026/2026-06-01
https://www.cisa.gov/known-exploited-vulnerabilities-catalog
https://www.cisa.gov/resources-tools/resources/kev-catalog
https://www.securityweek.com/check-point-vpn-zero-day-exploited-in-qilin-ransomware-attacks
https://www.securityweek.com/google-patches-5th-chrome-zero-day-exploited-in-2026
https://www.securityweek.com/solarwinds-patches-exploited-serv-u-vulnerability