Grundschutz++: Mehr Resilienz in der Informationssicherheit?
Der IT-Grundschutz des Bundesamtes für Sicherheit in der Informationstechnik (BSI) steht vor einer umfassenden Weiterentwicklung. Mit dem Grundschutz++ (GS++) löst das BSI die statische, dokumentenzentrierte Bereitstellung von Sicherheitsanforderungen im IT-Grundschutz-Kompendium ab und etabliert ein maschinenlesbares Regelwerk für die Ära der NIS-2-Richtlinie. Das BSI bildet das Regelwerk dabei in einem maschinenlesbaren digitalen Format (OSCAL/JSON) ab – ein Ansatz, der in der Fachwelt auch als „Compliance as Code“ oder „Rules as Code“ diskutiert wird (im Folgenden wird auf den Begriff „Compliance as Code“ referenziert). Durch die Konsolidierung der bisherigen 111 Bausteine auf 19 Praktiken eröffnet der GS++ das Potenzial, Informationssicherheitsmanagementsysteme (ISMS) von einem relativ statischen Konstrukt hin zu einem schrittweise automatisierbaren und agilen System weiterzuentwickeln. Hierbei strebt das BSI eine Harmonisierung mit der ISO/IEC 27001:2022 an. Parallel dazu werden die methodischen Eckpfeiler der BSI-Standards 200-x systematisch in ein digitales Format überführt.
Dieser Artikel geht auf die beiden folgenden Fragen ein:
- Wie kann die mit dem GS++ einhergehende Automatisierung die Resilienz eines ISMS steigern?
- Welche Herausforderungen können sich in der Umstellung auf GS++ in der Praxis ergeben?
Der GS++ schafft die strukturellen Voraussetzungen für eine kontinuierlich prüfbare Informationssicherheit und stärkt damit die organisatorische Resilienz. Der Übergang von einer punktuellen Momentaufnahme zur dauerhaften Überwachung des Soll-Ist-Zustands erfordert jedoch eine erhöhte technische Kompetenz aller Beteiligten und eine frühzeitige Investition in OSCAL-fähige Tools.
Vom statischen Katalog zum digitalen Regelwerk1
Seit Mitte der 1990er Jahre hat sich der IT-Grundschutz des BSI als frei verfügbare Vorgehensweise für die Umsetzung eines ISMS für Behörden, Unternehmen und Organisationen in Deutschland etabliert –unter anderem aufgrund der Verpflichtungen aus dem BSI-Gesetz und dem Umsetzungsplan Bund (UP Bund). Das ISMS definiert dabei den Rahmen für die systematische Steuerung, Überwachung und kontinuierliche Verbesserung der Informationssicherheit, um Geschäftsrisiken zu minimieren und die Resilienz zu stärken. In einer Welt von hochdynamischen Gefährdungsszenarien und agiler Softwareentwicklung stößt das bisherige Kompendium mit 111 Bausteinen und über 6.500 Teilanforderungen jedoch an seine Grenzen. Analysen und Erfahrungen aus der Beraterpraxis belegen, dass die umfangreiche Prosa des IT-Grundschutz-Kompendiums, regelmäßig zu Ungenauigkeiten bei der Maßnahmenumsetzung führt. Komplexe technische Abhängigkeiten in einem Informationsverbund lassen sich manuell kaum noch vollumfänglich und lückenlos pflegen.
Der GS++löst diese Problematik durch eine Verschlankung oder konkreter ausgedrückt durch eine Konsolidierung auf „atomare“ Anforderungen. Konkret heißt das als Zielbild: Einzeln prüfbare, eindeutig formulierte Sicherheitsanforderungen, die jeweils exakt einen Sachverhalt adressieren, führen zu einem erheblich praktikableren Setup. Die Anzahl der Anforderungen im GS++ reduziert sich auf rund 1000 Anforderungen, was einer quantitativen Straffung des Gesamtkatalogs um ca. 85 % entspricht. Diese Verschlankung ergibt sich aus einem umfangreichen Prozess, der vom BSI angeführt und von der Grundschutz++ Community mit fachlicher Expertise begleitet wird. Anforderungen wurden im Zuge dessen bereinigt, zusammengeführt und auf ihren wesentlichen Regelungsgehalt reduziert. Trotz dieser erheblichen Komplexitätsreduktion sollen keine sicherheitsrelevanten Detailaspekte im GS++ entfallen. Dies wird durch den Wechsel von der dokumentationslastigen und zielobjektorientierten Ausrichtung des IT-Grundschutz zu einer hierarchischen Zielobjekt-Kategorisierung erreicht. Sicherheitsanforderungen werden dabei nicht mehr für jedes einzelne Zielobjekt im Informationsverbund separat modelliert, sondern vererben sich entlang einer definierten Hierarchie von Kategorien auf untergeordnete Objekte – analog zum Vererbungsprinzip beim Schutzbedarf im klassischen IT-Grundschutz (z. B. von der Anwendung über das IT-System bis zur baulichen Infrastruktur). Die bisherigen drei Einstufungen des Schutzbedarfs sind im GS++ nun auf zwei Schutzniveaus (normal-SdT2/erhöht) reduziert.
| Metrik | IT-Grundschutz (Edition 2023) | Grundschutz++ |
| Anzahl Anforderungen | 6.567 (Teilanforderungen) | 985 (atomisierte Anforderungen) |
| Primäres Format | PDF (Prosa-Text) | OSCAL / JSON (maschinenlesbar) |
| Strukturierung | 111 Bausteine / 10 Schichten | 19 Praktiken (Governance, Personal etc.) |
| Einstufung | 3 Schutzbedarfs-Stufen (normal / hoch / sehr hoch) | 2 Sicherheitsniveaus (normal-SdT* / erhöht) |
| Fokus | Zielobjekt-orientiert | Prozess-orientiert |
| Update-Zyklus | Jährlich / statisch und langwierig | kontinuierlich und agil |
| Prüfbarkeit | manuell, stichprobenartig | Teil- oder vollautomatisierbare Prüfungen (Zielbild) |
Tabelle 1: Struktureller Vergleich IT-Grundschutz 2023 vs. Grundschutz++
Vier wesentliche Neuerungen können im Grundschutz++ im Vergleich zum IT-Grundschutz identifiziert werden:
- Governance-Shift – Verantwortlichkeit bei den Risikoeigentümern („risk owners“)
- Effizienz durch Konsolidierung – Praktiken statt Bausteine
- „Compliance as Code“ – Automatisierung mit OSCAL
- Methodische Migration und Überführung
Dieser Artikel fokussiert bewusst auf die Punkte (3) und (4), da sie im Hinblick auf die Umsetzung sowie Migration eines ISMS den operativen Handlungsbedarf für Organisationen definieren. Herausforderungen in der praktischen Umsetzung mittels ISMS-Tools werden thematisiert und Lösungswege aufgezeigt. Die Punkte (1) und (2) betreffen primär strategische und inhaltliche Entscheidungen auf Governance-Ebene und werden mitbetrachtet.
Compliance as Code
Zunächst ist das OSCAL-Format (Open Security Controls Assessment Language) als technologischer Kern des GS++ zu umreißen. OSCAL ist in drei logische Ebenen („layers“) unterteilt:
- Anforderungsebene bzw. Controls Layer (Kataloge und Profile)
- Implementierungsebene bzw. Implementation Layer (Komponenten-Modelle und System-Sicherheitspläne, sog. System Security Plans, SSP)
- Bewertungsebene bzw. Assessment Layer (Prüfpläne und Ergebnisse)
OSCAL strukturiert die Sicherheitsanforderungen in einem maschinenlesbaren Standard und ermöglicht so technische Interoperabilität zwischen ISMS-Tools und Katalogen. „Compliance as Code“ bezeichnet dabei die maschinenlesbare, versionierbare Repräsentation von Sicherheitsanforderungen und deren automatisierte Prüfbarkeit im institutionellen Kontext. CaC ermöglicht dabei das Ziel der Automatisierung, ist allerdings keine Voraussetzung für eine Implementierung oder Migration: So sieht die BSI-Methodik ausdrücklich vor, dass die Standardvorgehensweise auch ohne spezialisierte Werkzeuge durchgeführt werden kann. Perspektivisch empfiehlt das BSI jedoch, ein ISMS mit GS++ durch ein Tool zu betreiben. OSCAL selbst unterstützt die Formate JavaScript Object Notation (JSON), Extensible Markup Language (XML) und YAML (YAML Ain’t Markup Language). Das BSI hat sich beim GS++ für JSON als primäres Datenformat entschieden.
Anforderungen sind durch die drei folgenden Aspekte inhaltlich und technisch gekennzeichnet:
1. Atomisierung und Eindeutigkeit: Jede Anforderung ist atomar aufgebaut und besitzt einen Universally Unique Identifier (UUID), z. B. bf5d3cde-1c6b-4329-9a10-fdbe84279177. Dieser UUID erlaubt konzeptionell eine lückenlose digitale Rückverfolgbarkeit („traceability“). In der Katalog-Datei Grundschutz++-catalog.json ist jede Anforderung zusätzlich mit Metadaten über BSI-spezifische Namensräume („namespaces“) verknüpft. Diese Namespaces sind eine der zentralen Neuerungen des GS++: Sie erlauben eine mehrdimensionale algorithmische Filterung und Zusammenstellung von Anforderungen für spezifische Anwendungszwecke – etwa alle Anforderungen mit einem definierten Umsetzungsaufwand (Effort Level), für eine bestimmte Zielobjektkategorie (z. B. IT-Systeme) sowie mit einem Modalverb (MUSS, SOLLTE, KANN). Erst diese Systematik ermöglicht die anwendungsspezifische Auswahl und maschinelle Auswertung des Katalogs. Ein fehlerhafter Umgang mit diesen BSI-spezifischen Erweiterungen für Modalverben führt dabei unweigerlich zu inkonsistenten Compliance-Aussagen.
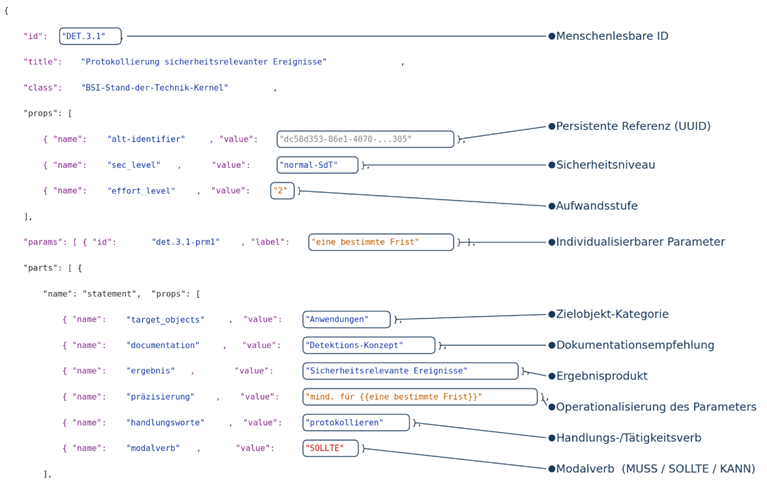
Abbildung 1: Aufbau einer GS++-Anforderung am Beispiel DET.3.1 – Protokollierung sicherheitsrelevanter Ereignisse
2. Parametrisierung: Anforderungen enthalten Platzhalter, wie z. B. {{ retention_period }}. für die Vorhaltungsdauer von Datensätzen Die hinterlegten Parameter erlauben es, das angestrebte Sicherheitsniveau einer Institution präzise im „Profile Model“ zu definieren, ohne den zugrundeliegenden Katalog zu verändern.
3. Kontinuierliche Aktualisierung: Die Anforderungen werden im Rahmen des GS++-Katalog über das GitHub-Repository „Stand-der-Technik-Bibliothek“ des BSI bereitgestellt und fortlaufend aktualisiert. Es kann von ISMS-Tools direkt abgerufen und verarbeitet werden. Technisch ausgedrückt erfolgt die Bereitstellung mithilfe einer Continuous Integration / Continuous Deployment (CI/CD)-Pipeline. Ein wesentlicher Vorteil des GS++ zum IT-Grundschutz liegt dabei nicht nur in der höheren Aktualisierungsfrequenz und der Geschwindigkeit, sondern in der Vollständigkeit: Automatisierte Systeme können alle vorliegenden Dokumente, Einträge und Konfigurationen lückenlos prüfen und kontinuierlich überwachen. Die automatisierte Validierung von Systemzuständen gegen den Anforderungskatalog (gewissermaßen als „Single Source of Truth“) kann die Fehlerquote durch menschliche Fehlinterpretationen reduzieren und erlaubt eine zeitnahe Reaktion auf Sicherheitsvorfälle – im Idealfall nahezu in Echtzeit. Wichtig ist dabei die konzeptionelle Trennung: Die kontinuierliche Aktualisierung des Anforderungskatalogs durch das BSI ist ein separater Prozess von der operativen Überwachung der Anforderungsumsetzung im ISMS des jeweiligen Informationsverbunds – letzterer erfordert eigene Mechanismen auf Systemebene (siehe Abschnitt zur Übersetzung bzw. „transition“).
Die maschinenlesbare OSCAL-Struktur eröffnet zudem Möglichkeiten der Kombination mit sprachverarbeitenden ML- bzw. KI-Modellen: Large Language Models (LLMs) können JSON-Daten maschinell auswerten und ihre Inhalte in natürlicher Sprache aufbereiten – etwa um Konformitätsanalysen von Konfigurationsdateien gegen den Anforderungskatalog darzustellen oder Hinweise zum Kontext eines Zielobjekt in der Umgebung (z. B. ein Switch im Netzwerk) für Verantwortliche zu generieren. Dies setzt jedoch eine sachgerechte Integration in den bestehenden Prüfprozess voraus und ersetzt keine regelbasierte Compliance-Prüfung.
Automatisierung als Treiber für Resilienz
Die beschriebenen Potenziale der Automatisierung der Anforderungsumsetzung wirken sich unmittelbar auf die Resilienz aus. Resilienz im Kontext eines ISMS bezeichnet die Fähigkeit einer Organisation, Sicherheitsvorfälle und regulatorische Veränderungen schnell zu erkennen, darauf zu reagieren und den Normalbetrieb kritischer Prozesse aufrechtzuerhalten. Vier Wirkpfade sind dabei besonders relevant:
- Die kontinuierliche, automatisierte Überprüfung von Systemkonfigurationen gegen den Anforderungskatalog verkürzt die Zeit zwischen dem Entstehen einer Abweichung und ihrer Entdeckung erheblich – im klassischen IT-Grundschutz wurde eine solche Lücke oft erst bei einem IT-Grundschutz-Check (GSC) oder Audit aufgedeckt. Die Reduktion dieser Reaktionszeit (Mean Time to Detect, MTTD) ist ein zentraler Faktor für operative Resilienz.
- Das automatisierte Versionsmanagement des Katalogs via Git ermöglicht es, dass regulatorische Änderungen am Stand der Technik zeitnah identifiziert und in den jeweiligen Informationsverbund überführt werden können. Dies unterstützt die Anpassungsfähigkeit des ISMS. Gemeint ist die Fähigkeit, das ISMS proaktiv an dynamische Bedrohungslagen anzupassen, anstatt auf festgestellte Gaps im Zuge von GSCs oder auf Findings aus Audits zu reagieren.
- Die Automatisierung entlastet die verantwortlichen Sicherheitsteams von Routineaufgaben, wie zum Beispiel der Generierung von Umsetzungsnachweisen, dem Abgleich von Soll- und Ist-Werten und der Dokumentationspflege. Die Automatisierung und KI-gestützte Prüfung erhöht gleichzeitig die Anforderungen an die technische Kompetenz der Beteiligten. Sicherheitsteams, Berater und Auditoren müssen künftig nicht nur Anforderungen kennen und dokumentieren. Sie müssen vielmehr verstehen, wie Konfigurationsdateien, z. B. von Servern, Firewalls und Anwendungen, aufgebaut sind, wie Prüfskripte funktionieren und wie API-Schnittstellen zwischen ISMS-Tools und IT-Systemen belastbar und zuverlässig gestaltet werden. Der GS++ verschiebt den Kompetenzschwerpunkt also von der Beherrschung von rein textlich formulierten Anforderungen hin zur technischen Durchdringung des Informationsverbunds.
- Bei einem Audit kann mithilfe der Verknüpfung der Systemkonfigurationen mit den Anforderungen folglich nicht nur das Vorhandensein einer dokumentierten Konfiguration überprüft werden, sondern auch mit geringem Mehraufwand die tatsächliche Umsetzung erfasst werden. Plakativ formuliert erfolgt eine Zertifizierung eines ISMS somit nicht mehr primär auf „Papierebene“ sondern auf Grundlage der tatsächlich umgesetzten und gelebten Informationssicherheit.
Ein praktisches Tool-Beispiel im Zusammenhang mit Audits ist, der von Sicherheitsexperten erstellte „BSI Audit Automator“. Das Tool verarbeitet bestehende Auditdaten, klassifiziert Quelldokumente nach BSI-Kategorien und generiert mehrstufig – hybrid aus KI-gestützter Analyse und deterministischer Berichtszusammenstellung – einen vollständigen BSI-Auditbericht im JSON-Format, einschließlich validierter Findings, Empfehlungen und Compliance-Assessment. Die Verarbeitung basiert auf zwei steuernden Konfigurationsdateien: einer strukturellen Blaupause (master_report_template.json), die definiert, was auditiert wird, und einer operativen Konfiguration (prompt_config.json), die steuert, wie auditiert wird. KI-gestützte Analysen und regelbasierte Auswertungen können sinnvoll kombiniert werden, um Zuverlässigkeit und Prüftiefe gleichzeitig zu gewährleisten.
Methodische Ansätze für eine effiziente Migration
Trotz der vom BSI angekündigten mehrjährigen Übergangsfrist bis zum Jahr 2029, sollten Unternehmen und Behörden möglichst frühzeitig operative Schritte einleiten:
- Strukturierte Mapping-Qualitätssicherung: Bestehende Sicherheitskonzepte müssen gegen die 19 neuen Praktiken des G++ validiert werden. Hierbei ist strikt zwischen direkter Übereinstimmung und indirekt unterstützenden Anforderungen zu unterscheiden, um Deckungslücken präzise zu identifizieren.
- Blaupausen als Schablonen: Das Konzept der Blaupausen ist die Weiterentwicklung der IT-Grundschutz-Profile. Es handelt sich um vordefinierte Vorlagen mit einer Auswahl relevanter Zielobjekte, Praktiken und zugehöriger Sicherheitsanforderungen, die Organisationen einen effizienten, risikoorientierten Top-down-Einstieg ermöglichen. Sie dienen also als wiederverwendbare Schablonen für spezifische Branchen, Organisationsstrukturen oder technische Kontexte (z. B. Cloud-Anwendungen). Eine Blaupause fungiert als „Profile Model“ in OSCAL, das Anforderungen aus verschiedenen Katalogen zusammenführt („merging“) und spezifisch auf das jeweilige ISMS ausrichtet und anpasst.
- Dach-Dokumente nutzen: Konsolidierte Dach-Dokumente (z. B. die ISMS-Leitlinie, IT-Betriebskonzept etc.) dienen als Ankerpunkte, um die Governance-Anforderungen des GS++ zentral zu erfüllen.
Umsetzung des GS++
Die technische Transformation des Regelwerks stellt insbesondere kleine und mittelständische Unternehmen (KMU) und Behörden mit einem ISMS vor eine signifikante Hürde: Da der Anwenderkatalog primär in maschinenlesbaren Formaten vorliegt, entfällt für ISMS-Tools ohne OSCAL-Unterstützung die Möglichkeit einer automatischen Verarbeitung. Zwar stellt das BSI den Katalog ergänzend auch als filterbare Excel-Datei bereit und betont eine stufenweise Einführung des GS++, die eine manuelle Bearbeitung ohne OSCAL-fähige ISMS-Tools grundsätzlich erlaubt. Für eine vollumfängliche Nutzung der UUID-basierten Verknüpfungen, der Namespace-Filterung und der Vererbungslogiken ist jedoch die Investition in ein OSCAL-fähiges Tool praktisch unumgänglich. Hieraus können sich im GS++ im Vergleich zur Umsetzung des IT-Grundschutz stärkere Abhängigkeiten von den eingesetzten Tools und den Herstellern ergeben. Die hiermit verbundenen Konsequenzen für das Lifecycle-Management (End of Life), Lizenzkosten und der Notwendigkeit kontinuierlicher Update-Zyklen sollten unbedingt berücksichtigt werden.
Außerdem ist im Auswahlprozess des ISMS-Tools sicherzustellen, dass es nicht nur das allgemeine OSCAL-Format unterstützt, sondern auch die BSI-spezifischen Erweiterungen (oscal_satzschablone_schema.json) verlustfrei verarbeiten kann. Es muss in der Lage sein, über Git veröffentlichte Änderungen mit den spezifischen Anpassungen des jeweiligen ISMS zusammenzuführen. Nur durch die Einhaltung dieser Anforderungen bleibt die Interoperabilität zwischen verschiedenen ISMS-Werkzeugen und dem Datenstrom des BSI gewährleistet.
Im Folgenden werden drei konkrete Herausforderungen anhand von Beispielen und Lösungen erörtert.
1) Inhaltliche Prüfung:
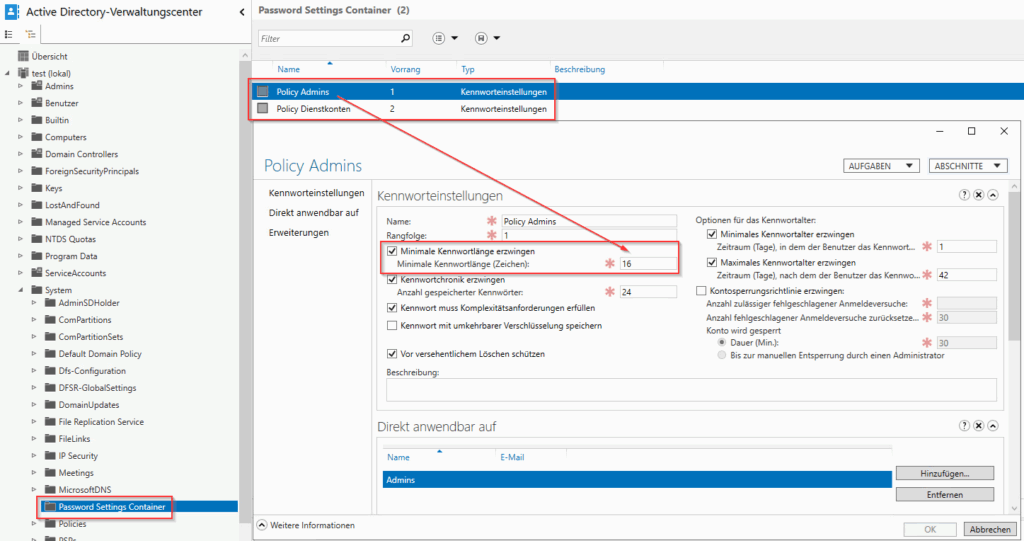
- Herausforderung: Ein Auditor möchte die Erfüllung der Anforderung zur Passwortkomplexität prüfen. Im GS++-Anwenderkatalog findet er lediglich die UUID und einen Platzhalter für einen Parameter. Ohne ein ISMS-Tool, welches die Anforderungen mit der Konfigurationsdatenbank des Informationsverbunds (Configuration Management Database, CMDB) verknüpft, kann der Auditor nicht nachvollziehen, welche spezifische Schutzbedarfskategorie einem System zugewiesen wurde und welcher individuell definierte Parameter-Wert (Soll-Vorgabe) somit für dieses Asset verbindlich ist.
- Lösung: Die CMDB dient als Kontextgeber. Das ISMS-Tool muss den im OSCAL-Profil definierten Soll-Wert (z. B. 14 Zeichen Passwortlänge) mit dem Kontext des jeweiligen Zielobjekts aus der CMDB verknüpfen, um festzustellen, auf welche Systeme diese spezifische Anforderung anzuwenden ist.
2) Versionsmanagement:
- Herausforderung: Da das BSI den Katalog über ein Repository auf GitHub bereitstellt („Stand-der-Technik-Bibliothek“) und kontinuierlich aktualisiert, können Modifikationen an einzelnen Anforderungen („Controls“) in der komplexen JSON-Datenstruktur manuell kaum identifiziert werden. Die revisionssichere Nachverfolgung von Änderungen am Stand der Technik ist ohne automatisierte Werkzeuge nicht mehr handhabbar. Außerdem droht ohne ein automatisiertes Revisionsmanagement eine vom Unternehmen oder der Behörde unbemerkte Abweichung der internen Dokumentation vom definierten Stand der Technik („Compliance-Drift“).
- Lösung: Das verantwortliche Team nutzt eine eigene Kopie des Anwenderkatalogs des BSI als „Fork“ des Git-Repositories. Idealerweise wird dieses in der eigenen Infrastruktur mit einer Registry betrieben, um sicherzustellen, dass schutzbedürftige Konfigurationsdaten nicht auf externen Plattformen verbleiben. Ein automatisierter Diff-Algorithmus vergleicht zyklisch die lokalen UUIDs mit dem Quellstand des BSI. Werden Änderungen detektiert, generiert das System automatisch einen Änderungsbeleg im ISMS-Tool. Dies ermöglicht es den Verantwortlichen, neue Anforderungen methodisch zu bewerten und gezielt zu entscheiden, ob diese in den aktuellen Informationsverbund übernommen oder für den laufenden Audit-Zyklus eingefroren werden.
3) Übersetzung („transition“):
- Herausforderung: Methodisch liegt eine Hürde in der Übersetzung („transition“) – die Verbindung zwischen abstrakter Governance und technischer Umsetzung. Die Governance fordert z. B. in der Praktik „Detektion (DET.3.1)“ eine Protokollierung für 30 Tage. Das verantwortliche Team nutzt jedoch automatisierte Skripte, die lediglich 14 Tage vorsehen.
- Lösung: Ein Skript prüft täglich die Vorgaben zur Aufbewahrung („
retention_policy“)am Server. Das Ergebnis wird per Programmierschnittstelle („application programming interface“, API) an das ISMS-Tool gemeldet. Weicht der Wert vom definierten Parameter ab, wird automatisch ein Ticket im Änderungsmanagement („change management“) ausgelöst und der zuständigen Stelle zur Anpassung zugeführt. Dies überführt die Compliance-Prüfung von einem periodischen in einen kontinuierlichen Prozess. Dieses Vorgehen – das automatisierte Auslesen und strukturelle Auswerten („parsen“) von Konfigurationsdateien, z. B. aus Servern, Firewalls, Verzeichnisdiensten und weiteren Anwendungen, wird im Kontext des GS++ erheblich an Bedeutung gewinnen. Sobald Anforderungen als parametrisierte OSCAL-Objekte vorliegen, lassen sich Soll-Werte direkt gegen maschinenlesbare Konfigurationsartefakte der IT-Infrastruktur abgleichen. Werkzeuge für CaC-Frameworks (z. B. Chef InSpec, Open Policy Agent) sind für genau diesen Zweck konzipiert. Technisch wird dieser Vorgang in der Implementierungsschicht abgebildet. - Kritische Würdigung: Es ist zu beachten, dass Automatisierung keine Allzwecklösung darstellt. Da APIs für verschiedene Serverlandschaften und Anwendungen oft proprietär und nicht durchgängig standardisiert sind, werden wahrscheinlich nicht alle Zielobjekte im Informationsverbund nahtlos an das eingesetzte ISMS-Tool angebunden werden können. Zudem besteht die Gefahr einer „Automatisierungs-Hörigkeit“, bei der sich Verantwortliche zu stark auf digitale Kennzahlen verlassen und nicht-automatisierte Kontrolllücken (z. B. hinsichtlich der physischen Sicherheit oder sozialen Aspekte) übersehen. Die Methodik des GS++ trägt diesem Umstand Rechnung, indem neben technisch-automatisierten Methoden auch Interviews, Dokumentenprüfungen, Beobachtungen und Stichproben als legitime Prüfmethoden im Rahmen eines Auditprogramms vorgesehen sind.
Fazit: Resilienz messbar machen
Zu den beiden eingangs gestellten Fragen lässt sich abschließend Folgendes festhalten: Der GS++ steigert die Resilienz eines ISMS messbar – durch die Reduktion der Erkennungszeit bei Konfigurationsabweichungen, die automatisierte Nachverfolgung von Katalogänderungen via Git sowie die Entlastung von Sicherheitsteams bei der Generierung von Umsetzungsnachweisen. Sobald die im GS++ angelegten Kennzahlen und Metriken vollständig definiert und in ISMS-Tools implementiert sind, sind die Grundlagen geschaffen, Resilienz als strategisches Ziel zu operationalisieren. Das Management erhält datenbasierte Entscheidungsgrundlagen über den tatsächlichen Sicherheitszustand des ISMS und des gesamten Informationsverbunds. Der Prüfprozess wird hierbei umfassender und tiefer, der Anspruch an die fachliche und technische Qualität insgesamt steigt. Konkret verdeutlichen die praktischen Beispiele zur Passwort-Komplexitätsprüfung, zum Versionsmanagement und zur automatisierten Überwachung der Retention Policy, dass der Übergang eine Integration der CMDB, OSCAL-fähige Tools und ausgeprägte technische Kompetenz in allen beteiligten Rollen voraussetzt – wer diese Voraussetzungen nicht erfüllt, läuft Gefahr, die strukturellen Vorteile des GS++ nicht auszuschöpfen.
Die Weiterentwicklung des G++ gegenüber dem klassischen IT-Grundschutz resultiert aus der konsequenten Anwendung der OSCAL-Schichten-Architektur: Während die Anforderungsschicht („Controls Layer“) die regulatorische Stabilität bietet, erlaubt die Implementierungsschicht („Implementation Layer“) perspektivisch eine hochgradig automatisierte Abbildung der technischen Realität. Die größte Herausforderung ist hierbei nicht der inhaltliche Kern, sondern die Fähigkeit von Unternehmen und Behörden, den Übergang zum „Compliance as Code“-Modell proaktiv durch den Aufbau digitaler Schnittstellen und die Einführung spezialisierter Tools zu gestalten. Dies fördert die Skalierbarkeit der Sicherheitsprozesse und überführt regulatorische Anforderungen von einer weithin statischen Dokumentationspflicht in einen kontinuierlich messbaren Steuerungsprozess.
Referenzen
BSI: Ein Vierteljahrhundert Informationssicherheit: IT-Grundschutz mit Methode, Pressemitteilung, 7. Oktober 2019.
URL: https://www.bsi.bund.de/DE/Service-Navi/Presse/Pressemitteilungen/Presse2019/25-Jahre-IT-Grundschutz_07102019.html
BSI: IT-Grundschutz-Kompendium, Edition 2023, 1. Februar 2023.
URL: https://www.bsi.bund.de/DE/Themen/Unternehmen-und-Organisationen/Standards-und-Zertifizierung/IT-Grundschutz/IT-Grundschutz-Kompendium/it-grundschutz-kompendium_node.html
BSI: Übersicht konsolidierte DA im IT-Grundschutz, Stand Kompendium 2023, 27. Juni 2024.
URL: https://www.bsi.bund.de/SharedDocs/Downloads/DE/BSI/Grundschutz/Drafts/Community_Draft/Uebersicht_DA-IT-Grundschutz_Kompendium_2023.xlsx?__blob=publicationFile&v=3
BSI: Pressemitteilung: BSI veröffentlicht Stand-der-Technik-Bibliothek auf GitHub, 30. September 2025.
URL: https://www.bsi.bund.de/DE/Service-Navi/Presse/Alle-Meldungen-News/Meldungen/Stand-der-Technik-Bibliothek_250930.html
BSI: Stand der Technik
URL: https://www.bsi.bund.de/DE/Themen/Unternehmen-und-Organisationen/Standards-und-Zertifizierung/Grundschutz-in-der-Informationssicherheit/Stand-der-Technik/stand-der-technik.html
BSI: IT-Grundschutz-Tools
URL: https://www.bsi.bund.de/DE/Themen/Unternehmen-und-Organisationen/Standards-und-Zertifizierung/IT-Grundschutz/IT-Grundschutz-Kompendium/Alternative-IT-Grundschutztools/IT-Grundschutztools.html
BSI: Stand-der-Technik-Bibliothek (GitHub-Repository), Stand: 16. März 2026.
URL: https://github.com/BSI-Bund/Stand-der-Technik-Bibliothek
BSI: OSCAL-Dokumentation, in: Stand-der-Technik-Bibliothek (GitHub-Repository), Stand: 16. März 2026.
URL: https://github.com/BSI-Bund/Stand-der-Technik-Bibliothek/blob/main/Dokumentation/OSCAL.md
BSI: Diskussionspapier zur Modernisierung der Methodik-Grundschutz ++ (Version: 0.9), Stand: 6. Februar 2026.
ISMS-Ratgeber Wiki: Migration von IT-Grundschutz zu Grundschutz++, Stand: 5. Februar 2026.
URL: https://wiki.isms-ratgeber.info/wiki/Grundschutz++Migration
ISMS-Ratgeber Wiki: Grundschutz++ Einführung und Aufbau, Stand: 13. März 2026
URL: https://wiki.isms-ratgeber.info/wiki/Grundschutz++_Einführung_und_Aufbau
Lorenz, Reto; Künkel, Daniel: „Grundschutz++ – Der BSI-Weg zur agilen Sicherheit“, in: IT-SICHERHEIT, 4. August 2025, Ausgabe 3/2025.
URL: https://www.itsicherheit-online.com/security-management/grundschutz-der-bsi-weg-zur-agilen-sicherheit/
Neweling, Benjamin: Deep-Dive ins neue Kompendium (Vortrag), 18. Februar 2026.
URL: https://www.youtube.com/watch?v=bqic_4xUZT0
NIST: OSCAL Layers and Models, 26. Januar 2026.
URL: https://pages.nist.gov/OSCAL/learn/concepts/layer/
Puppe, Christoph: „Experiment: KI entwickelt ISMS-Standard weiter“, in: iX Magazin, 15. September 2025.
URL: https://www.heise.de/hintergrund/Experiment-KI-entwickelt-ISMS-Standard-weiter-10624585.html
Reinhardt, Sebastian; Schiele, Hendrik; Helani, Kinan: „Grundschutz++: Migration und Mapping“, in: <kes> – Zeitschrift für Informationssicherheit, Ausgabe 1/2026, 23. Februar 2026. S. 6-9.
URL: https://www.kes-informationssicherheit.de/print/titelthema-it-grundschutz-2/grundschutz/
Reinhardt, Sebastian: IT-Grundschutz++ – auf dem Weg zum digitalen Regelwerk, in: <kes>, 17. April 2025.
URL: https://www.kes-informationssicherheit.de/print/titelthema-metriken-und-kennzahlen/it-grundschutz-auf-dem-weg-zum-digitalen-regelwerk/
Reinhardt, Sebastian: IT-Grundschutz zu Grundschutz++ (Vortrag), 18. Februar 2026.
URL: https://www.youtube.com/watch?v=I93WCKAu524
Weiß, Jonathan: Blaupausen im Grundschutz++ (Vortrag), 18. Februar 2026.
URL: https://www.youtube.com/watch?v=oq8Zym9cwnY
1 Hinweis: Die nachfolgenden Ausführungen basieren auf dem aktuellen Entwicklungsstand des BSI-Anwenderkatalogs und dem Diskussionspapier zur Modernisierung der Methodik-Grundschutz++ (Januar 2026).
2 SdT: Stand der Technik ist der Entwicklungsstand fortschrittlicher Verfahren, Einrichtungen oder Betriebsweisen, der die praktische Eignung einer Maßnahme zum Schutz von IT-Systemen gegen Beeinträchtigungen der Verfügbarkeit, Integrität, Authentizität und Vertraulichkeit gesichert erscheinen lässt. Der Stand der Technik liegt rechtssystematisch zwischen den allgemein anerkannten Regeln der Technik und dem Stand der Wissenschaft und Forschung. Maßgeblich sind einschlägige Normen und Standards (z. B. ISO-Standards) sowie in der Praxis erprobte Verfahren.