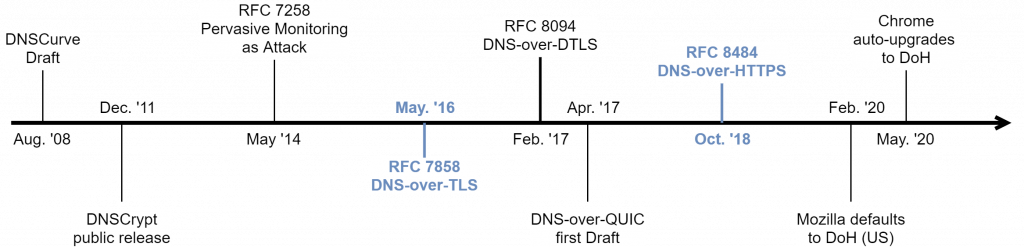
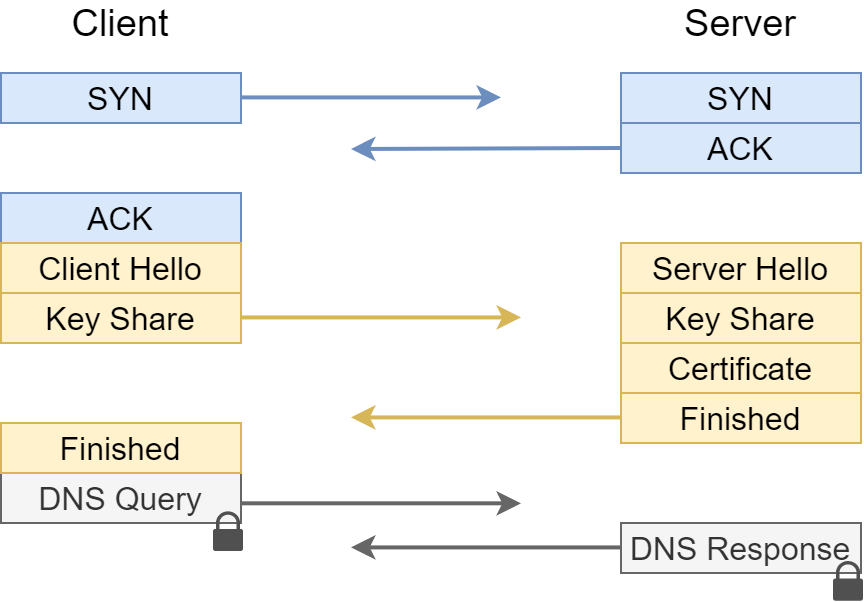
Perimeter Defense
Zuletzt häuften sich erneut herstellerübergreifend die Sicherheitslücken in Firewalls, also gerade in den Geräten, die die Umgebung eigentlich schützen sollten. Die Rolle der Perimeterverteidigung wird nunmehr infrage gestellt und Zero Trust nicht nur als neues Buzzword verwendet, sondern auch als innovative Lösung der Hersteller versprochen.
Das Konzept dahinter ist aber gar nicht so innovativ: Bereits 1994 wurde „Zero Trust“ im Rahmen einer Dissertation definiert. Über die Jahre finden sich viele weitere Talks und Beiträge, die gegen Firewalls als alleinige Sicherheitskonzepte plädieren, aber auch die grundsätzliche Rolle dieser Geräte hinterfragen. Eine eindeutige Definition des Begriffes „Zero Trust“ wird zunehmend durch die Derivationen der Hersteller schwieriger, aber das Konzept ist recht simpel: statt einer geschützten Grenze zwischen dem „bösen“ Internet und dem „guten“ Intranet wird das gesamte Transportmedium als grundsätzlich nicht vertrauenswürdig angesehen. Ein Schutz der Daten findet dann direkt über das Anwendungsprotokoll statt.
Wenngleich der Begriff das Misstrauen gegenüber allen beteiligten Instanzen suggeriert, verbleibt die Notwendigkeit dem Anbieter einer solchen Lösung zu vertrauen. Das heißt wie auch schon heute mit Firewalls ist dessen Reputation entscheidend. Besonders klar machte uns das die Meldung über die Ausnutzung eben dieser besonderen Privilegien durch das X-Ops Team von Sophos, um eine chinesische APT-Gruppe zu verfolgen, indem die Sicherheitsforschenden eigene Malware auf den Geräten hinterlegten.
Wie so oft ist die vorgestellte Lösung also nicht das Allheilmittel, es ist weiterhin wichtig alle Optionen im Blick zu haben und die beste Umsetzung für die eigene Umgebung auszuwählen.
https://www.wired.com/story/sophos-chengdu-china-five-year-hacker-war
https://news.sophos.com/en-us/2024/10/31/pacific-rim-neutralizing-china-based-threat/
https://www.securityweek.com/security-perimeter-dead
https://media.ccc.de/v/gpn21-88-perimeter-security-is-dead-get-over-it-